Longformer: The Long-Document Transformer 논문 정리
Longformer: The Long-Document Transformer
|
|
Longformer |
Transformer |
|
complexity |
O(n^2) scales linearly |
O(n) scales quadratically |
|
attention |
local windowed attention + global attention (d) |
self-attention (a) |
|
max length |
4,096 |
512 |
[ Attention Pattern ]
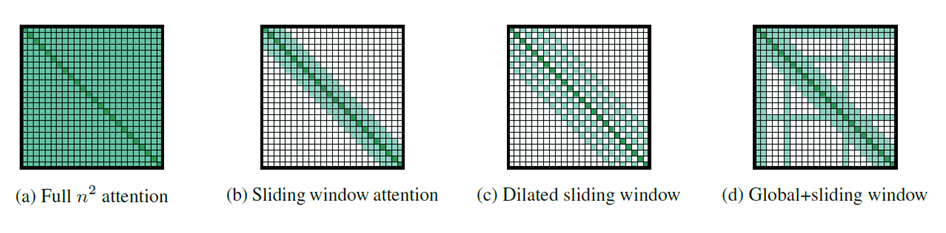
1) Sliding Window
• fixed-size window attention for local context
• complexity: O(n × w)
• n: input sequence length
• w: fixed window size (layer마다 달라질 수 있음)
|
small window size |
large window size |
|
local information |
higher-level representation |
|
efficiency |
performance |
• stacking layers lead to high level features (similar w/ CNN)
• receptive field size: l × w
• l: num of layers
2) Dilated Sliding Window
• analogues to dilated CNN
• window has gaps of size dilation

• receptive field size: l × d × w
• d: size dilation
3) Global Attention
• to learn task-specific representations
• add global attention on few pre-selected input locations
ex) classification task: [CLS] token, QA task: all question tokens
• symmetric
• a token with a global attention attends to all tokens
• all tokens attend to a token with a global attention
[ Pretraining and Finetuning ]
• continues from the RoBERTa checkpoint (instead of pretraining from scratch)
• sliding window attention w/ window size 512
• add extra positional embeddings (up to 4,096)
• copy 512 positional embedding from RoBERTa (instead of randomly initializing)
cf. BigBird Model’s attention
참고
longformer original paper: https://arxiv.org/pdf/2004.05150.pdf
BigBird paper explained: https://youtu.be/WVPE62Gk3EM