2020. 6. 24. 13:30ㆍnlp
수년간 겪어온 맨스플레인을 바탕으로 쓴 글.
이론적 배경을 보충하고 싶어서 맨스플레인 관련 논문 찾아봤는데 거의 없더라. 내가 잘못찾은건가
그냥 단행본에서 만든 신조어라 논문이 없나봐
• 정보구조란?
화자가 발화를 통해 전달하려는 정보가 청자에게 새로운 것인지, 주어져 있는 것인지에 대한 화자의 가정을 반영하는 언어적 양상 (최윤지(2016): 한국어 정보구조 연구)
→ 내 경험상 누가봐도 내가 더 잘 알 것 같은 내용을 지만 아는 것처럼 말한다든지, 말하면서 이미 나온 얘기인데 혼자 알고 있는 것마냥 말하는 사람들은 다 남자였다. 그래서 세종 구어 코퍼스로 이를 확인해봤다.
사실 저번에 '지붕뚫고 하이킥' 대본으로 간략히 분석해본 적이 있다. 결과는 망했다.
이번엔 성공해서 다행이다.
이땐 너무 생각없이 '-거든'에만 꽂혀서 망한 거 같은데 이번엔 어떤 문맥에 사용된 '-거든'이 내가 말하는 '-거든'의 의미로 쓰였는지 알아내서 이 문맥으로만 제한해서 살펴보니 성공했다.
https://codlingual.tistory.com/7
하이킥 대본 후다닥 분석
맨스플레인(mansplain)은 남자(man)와 설명하다(explain)를 결합한 단어로, 대체로 남자가 여자에게 의기양양하게 설명하는 것을 말한다 (from Wiki ^^) 내가 지금까지 겪어본 맨스플레인들은 1) 뭐냐면 2)
codlingual.tistory.com
정보구조를 전략적/규범적 정보구조로 나눠보면 다음과 같다.
- 전략적 정보구조: 신정보를 구정보처럼 제시 (담화에 새로운 내용을 제시할 때 청자가 이를 알 것을 전제하고 말함)
- 규범적 정보구조: 신정보를 신정보처럼 제시 (담화에 새로운 내용을 제시할 때 청자가 이를 모를 것을 전제하고 말함)
담화 내 새로운 정보를 제시할 때, 여성은 전략적 정보구조를, 남성은 규범적 정보구조를 더 많이 사용할 것이란 가설을 세웠다.
1) 담화 내 새로운 정보를 제시하는 문맥인지 알아내기: X이라는 Y
- 고유명사나 일반명사 를 X 자리에 취하고 X보다 더 일반적인 의미를 가지는 ‘것’과 같은 명사를 Y 자리에 취하는 구성(최윤지 2016:94)
(ex) 화자와 청자 모두 알고 있는 사람이라면 "김OO 있잖아~"처럼 그냥 이름을 말하지만 청자가 모르는 사람이라면 "김OO이라는 애가 있는데~" 등으로 지칭한다.
cf. 이 중 이미 나온 주제지만 다시 초점을 맞추기 위해 'X이라는 Y' 구성을 사용한 경우는 제외하고 분석함
# 'X이라는 Y', 단, X는 보통명사 또는 고유명사로 한정
def check_new(speech):
new_speech = []
num = len(BeautifulSoup(speech).find_all('s'))
for i in range(num):
string = str(BeautifulSoup(speech).find_all('s')[i])
if '/NNG+이/VCP+라는/ETM' in string or '/NNP+이/VCP+라는/ETM' in string:
new_speech.append(string)
else:
continue
return new_speech
df['신정보speech'] = df['speech'].apply(lambda x:check_new(x))
# 'X이라는 Y'를 한번 이상 한 사람들의 speech만 남기기
new_df = df[df['신정보speech']!='[]']
- 'X이라고' 구성으로 신정보를 제시하는 발화도 있었지만, '이라고' 패턴을 포함하면 쓰레기도 너무 많이 포함되어서 패턴 자체를 버렸다.
- 이렇게 신정보를 제시하는 발화를 추출하고 이제 발화 하나당 row 하나로 dataframe 구조를 바꾼다. 근데 화자/청자의 성별, 대화상황 등의 정보는 그대로 필요하니까 이 정보들도 같은 row에 포함시키기
from bs4 import BeautifulSoup
line_df = pd.DataFrame(columns=['filename', 'speaker', 'gender', 'listener','job','setting','age',\
'new_speech'])
count=0
for i in range(len(new_df)):
speech = BeautifulSoup(new_df['신정보speech'][i]).find_all('s')
for j in range(len(speech)):
filename = new_df.iloc[i,0]
speaker = new_df.iloc[i,1]
gender = new_df.iloc[i,2]
listener = new_df.iloc[i,43]
job = new_df.iloc[i,42]
setting = new_df.iloc[i,3]
age = new_df.iloc[i,29]
new_speech = speech[j]
line_df.loc[count] = [filename, speaker, gender, listener, job,setting,age,new_speech]
count+=1
- 그런데 여기까지 하면 신정보를 제시하는 발화가 저렇게 나온다. 그래서 cleaning이 필요
<s n="00322">\\\\r\\\\r\\\\r\\\\r\\\\r\\\\r\\\\n5CT_0034-0022640\\\\t거기가\\\\t
거기/NP+가/JKS\\\\r\\\\r\\\\r\\\\r\\\\r\\\\r\\\\n5CT_0034-0022650\\\\t피피섬이라는\\\\t
피피섬/NNP+이/VCP+라는/ETM\\\\r\\\\r\\\\r\\\\r\\\\r\\\\r\\\\n5CT_0034-0022660\\\\t데거든요,
\\\\t데/NNB+이/VCP+거든요/EF+,/SP\\\\r\\\\r\\\\r\\\\r\\\\r\\\\r\\\\n5CT_0034-0022670\\\\t</s>
- 완벽하진 않지만 이렇게 하면 알아보기 쉬운 상태로는 바뀐다.
거기가 피피섬이라는 데거든요,
import re
def clean(string):
string = string.replace('\\\\\\\\r\\\\\\\\r\\\\\\\\r\\\\\\\\r\\\\\\\\r\\\\\\\\r\\\\\\\\n', ' ')
string = string.replace('\\\\\\\\t', ' ')
pattern = '[가-힣]'
tokens = string.split(' ')
sent = []
for i in range(len(tokens)):
if re.search(pattern, tokens[i]) and '/' not in tokens[i]:
sent.append(tokens[i])
return ' '.join(sent)
- 여기까지 완성된 df (이건 '이라고' 패턴을 포함한 버전의 df인데 이후엔 이 버전 버렸다)
- speaker는 한 파일 내에서 발화자 구분을 위해 코퍼스 내에 있던 표시 그대로 가져온 것, gender는 화자의 성별, listener는 청자의 성별(column 이름을 좀 수정해야 할 것 같지만 그냥 냅뒀다...), job은 코퍼스에 제시된 발화자 직업 등등
2) 어떤 정보구조 사용했는지 알아내기: 종결어미
- 선행연구를 참고해서 종결어미를 분류했다. 사실 '정보구조를 드러내지 않음'/'청자의 지식수준을 확인함' 이 부분은 선행연구를 못 찾았는데 그냥 한국인의 직관으로^^ 분류했다.
- 세종구어코퍼스에 나타난 변이형을 모두 포함하여 정리
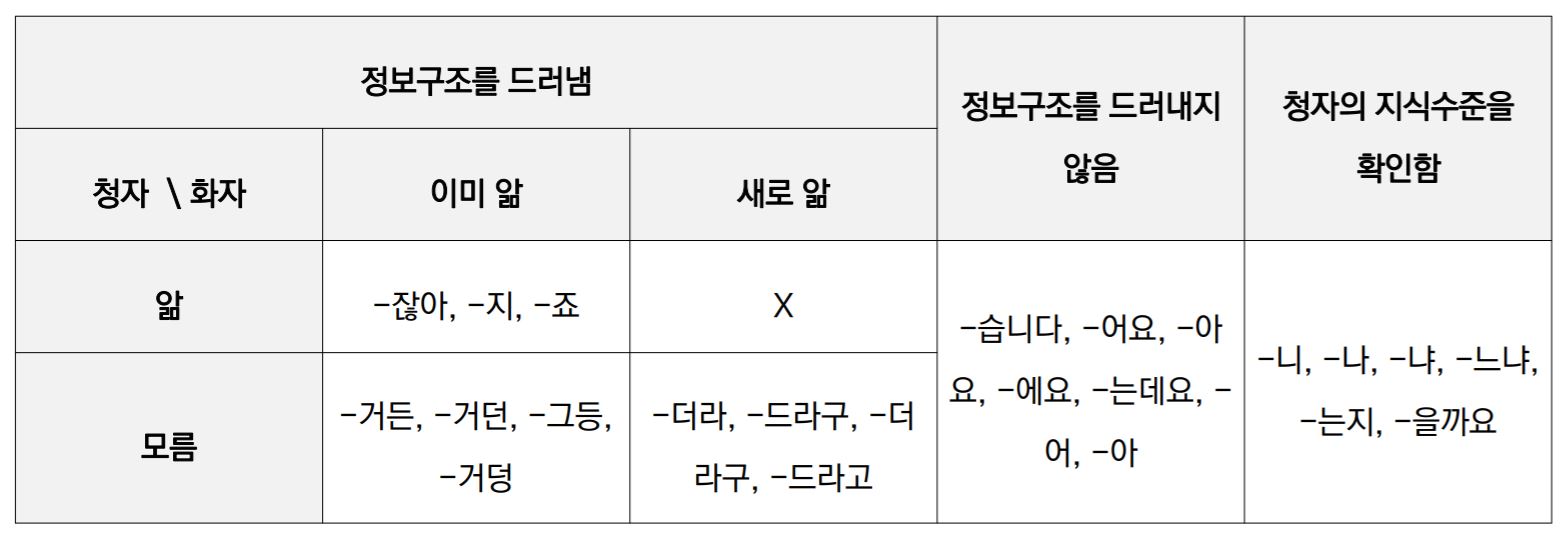
- 화자와 청자 모두 안다고 가정하는 종결어미(전략적 정보구조)로 '-잖아', '-지' 등이 있고 화자는 아는데 청자는 모른다고 가정하는 종결어미(규범적 정보구조)로 '-거든'이 있다.
cf. 'X이라는 Y' 구성과 종결어미가 관계 없는 경우는 제외하고 분석함
- 내가 갖고 있는 코퍼스에선 '-잖아'를 하나의 종결어미로 태깅하지 않았다. 그래서 종결어미 추출하는 함수에 '잖'이 앞에 있는 종결어미 '아'는 '잖'과 합쳐서 '잖아'를 종결어미로, 그 외는 /EF로 태깅된 걸 종결어미로 가져왔다.
def find_ef(speech):
if '잖/EP' in speech:
pattern = '잖/EP\+[가-힣]*?/EF'
else:
pattern = '(?<=\+)[가-힣]*?/EF'
match = re.search(pattern, speech)
if match:
return match.group()
else:
return ''
df['종결어미'] = df['new_speech'].apply(lambda x : find_ef(x))
- 이렇게 받아온 종결어미 종류를 다 뽑아보는 코드
from collections import Counter
Counter(df['종결어미'])
- 이 다음은 저 표에 정리한 대로 종결어미 리스트 만들고 종결어미가 어느 리스트에 있느냐 따라서 정보구조를 나눠줬다.
1. 화자의 성별에 따라
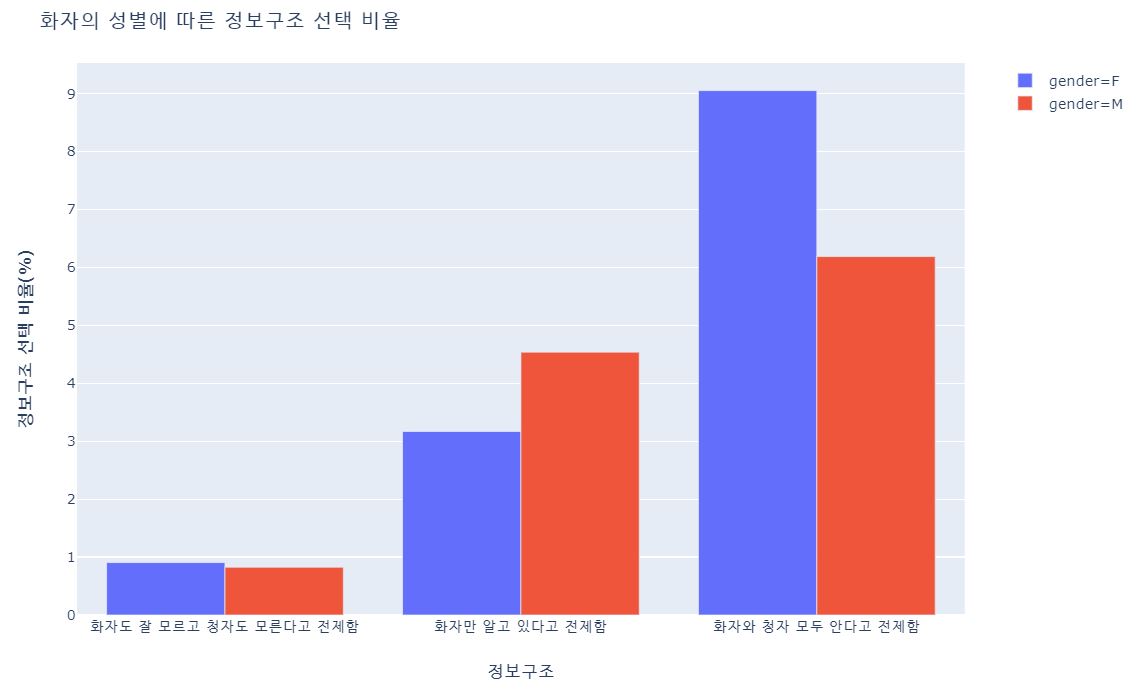
- 여성 화자는 남성 화자보다 화자와 청자가 모두 안다고 전제한 경우가(전략적 정보구조), 남성 화자는 여성화자보다 화자만 알고 있다고 전제한 경우가(규범적 전략구조) 많았다.
- 여자가 전략적 정보구조를, 남자가 규범적 전략구조를 더 많이 사용한다는 건 p값 < 0.1, 통계적으로 유의미하게 나타났다
- 근데 내가 제대로 통계를 돌렸는진 모르겠다
- n은 각 성별마다 정보구조를 표현한 발화 수이다. 정보구조를 드러내지 않은 발화가 드러낸 발화보다 많아서, 일단 정보구조를 드러냈을때! 어떤 정보구조를 선택하는지 알고 싶어서
prop <- c(0.04761905,0.023)# proportion of events
n <- c(126, 128) # number of trials
x <- prop*n # number of events
prop.test(x = x,n = n,alternative = c("two.sided"), conf.level = 0.95)
# confidence level (= 1- significance level 'alpha')
- 이건 그래프 그리는 코드. 저번 학기부터 plotly를 애용하고 있다.
import plotly.express as px
mean = df.groupby('gender').mean()[['화자도 잘 모르고 청자도 모른다고 전제함',\
'화자만 알고 있다고 전제함','화자와 청자 모두 안다고 전제함']]*100
mean = mean.reset_index()
mean = pd.melt(mean, id_vars=['gender'], value_vars=['화자도 잘 모르고 청자도 모른다고 전제함',\
'화자만 알고 있다고 전제함','화자와 청자 모두 안다고 전제함'], var_name='정보구조',value_name='비율')
fig = px.bar(mean, x="정보구조", y="비율", color='gender', barmode='group')
fig.update_layout(title="화자의 성별에 따른 정보구조 선택 비율", yaxis_title = "정보구조 선택 비율(%)")
fig.show()
- 원래 ['화자도 잘 모르고 청자도 모른다고 전제함','화자만 알고 있다고 전제함','화자와 청자 모두 안다고 전제함'] 얘네들이 column이었는데 pd.melt를 해서 value가 된다.
- 돌려놓은 게 없어서 뒤죽박죽인 예시이지만 쨌든 column을 value 값으로 바꿔주는게 pd.melt


2. 청자의 성별에 따라
청자의 성별도 똑같은 방식으로 했다.
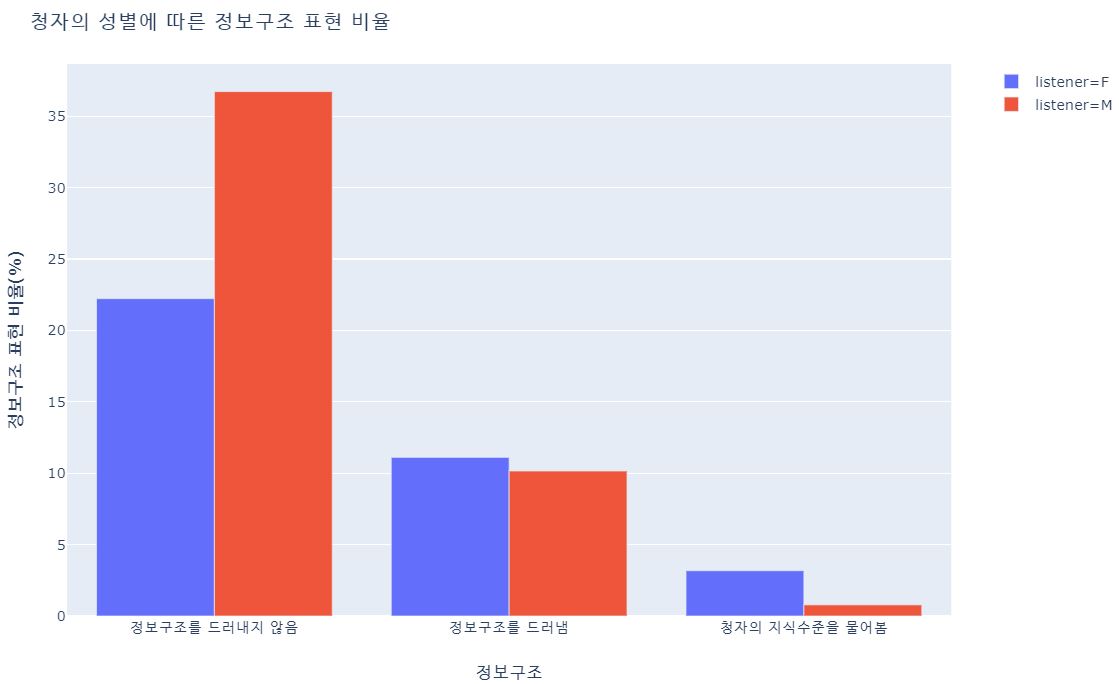
- 청자가 남성일 때, 청자가 여성일 때보다 정보구조를 드러내지 않는 경우가 많았다. p값 < 0.05
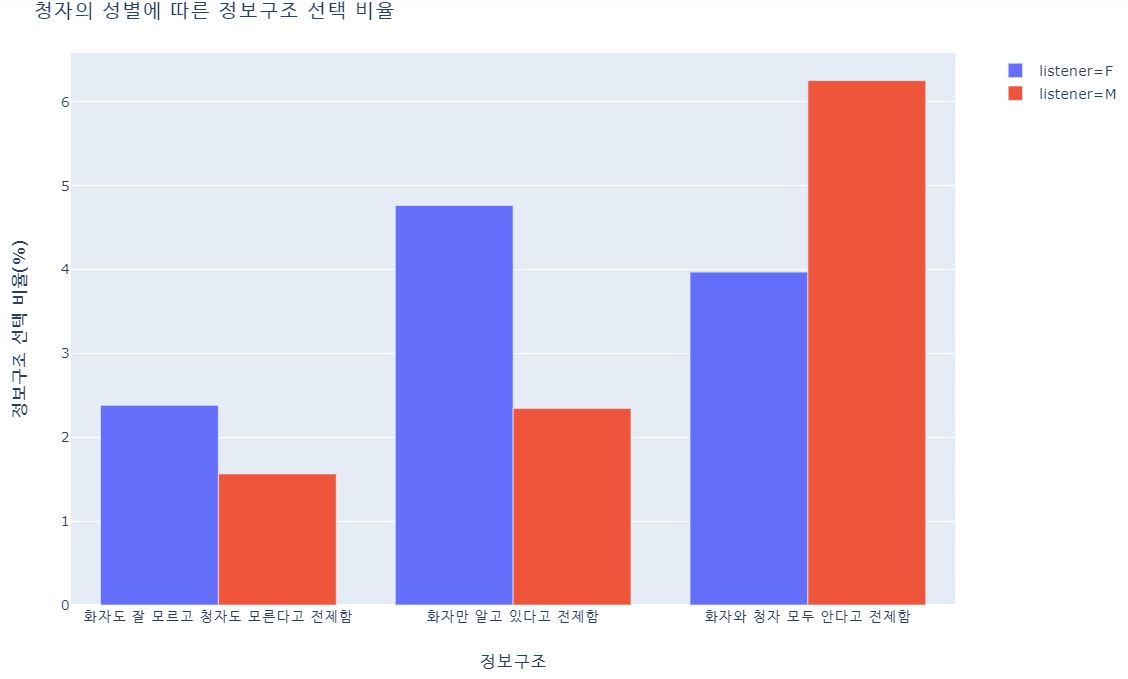
- 앞의 두 경우는 청자가 모른다고 전제한 경우, 세번째 경우는 청자도 안다고 전제한 경우
- 앞의 두 경우는 남성 청자보다 여성 청자의 비율이, 세번째 경우는 여성 청자보다 남성 청자의 비율이 더 높았다.
- 청자의 성별은 대화 참여자가 2명밖에 없을 때만 알 수 있어서 표본이 작다. 그래서 통계적 유의성은 나타나지 않았지만 내 경험상 충분히 유의하다 ㅎ;
'nlp' 카테고리의 다른 글
| 임베딩Embedding 정리 (0) | 2021.02.25 |
|---|---|
| 알파벳으로 한글 쓰기 0r2#rld7lxolNJ 6rLrlN ^^-7l (0) | 2020.10.27 |
| FNN, CNN, RNN 구조 비교 (0) | 2020.05.22 |
| 세종구어코퍼스에서 종결어미/선어말어미만 추출하기 (0) | 2020.05.10 |
| 세종 구어 말뭉치(tei 포맷) csv로 변환하기 (0) | 2020.05.10 |