2020. 2. 4. 02:05ㆍnlp
1. Matrices
https://www.deeplearningwizard.com/deep_learning/practical_pytorch/pytorch_matrices/
Matrices - Deep Learning Wizard
Matrices with PyTorch Matrices Matrices Brief Introduction 2 x 2 Matrix (R x C) 2 x 3 Matrix Creating Matrices Create list # Creating a 2x2 array arr = [[1, 2], [3, 4]] print(arr) Create numpy array via list # Convert to NumPy np.array(arr) array([[1, 2],
www.deeplearningwizard.com
• numpy array를 tensor로 변환하기
import torch
torch.Tensor(<np_array>)
torch.from_numpy(<np_array>)
• tensor를 numpy array로 변환하기
torch_tensor.numpy()
• 특정 값으로 이루어진 tensor 만들기
torch.ones((2,2)) # size=(2,2)
• 랜덤한 값으로 이루어진 tensor 만들기
torch.rand(2,2) # size=(2,2)
•랜덤한 값 변하지 않게(fix) 하도록 seed
np.random.seed(0)
torch.manual_seed(0)
• default 상태는 CPU
• CPU에서 GPU로 변환
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tensor_cpu.to(device)
• GPU에서 CPU로 변환
tensor_cpu.cpu()
• reshape/resize
a = torch.ones(2,2)
a.size() #2,2
a.view(4)
a.size() #4
•원소별 덧셈 Element-wise addition
a + b
torch.add(a, b)
•in-place 원소별 덧셈
* in-place = 원래 tensor 자체가 수정된다는 의미
c #[[2,2], [2,2]]
c.add_(a)
c # [[3,3], [3,3]]
•원소별 뺄셈 Element-wise subtraction
a - b
a.sub(b)
•in-place 원소별 뺄셈
a.sub_(b)
•원소별 곱셈
a * b
torch.mul(a,b)
•in-place 원소별 곱셈
a.mul_(b)
•원소별 나눗셈
b / a
torch.div(b,a)
•in-place 원소별 곱셈
b.div_(a)
•tensor의 평균 구하기
a.mean(dim=0)
a.mean(dim=1)
•tensor의 표준편차 구하기
a.std(dim=0)
2. Linear Regression with PyTorch
https://www.deeplearningwizard.com/deep_learning/practical_pytorch/pytorch_linear_regression/
Linear Regression - Deep Learning Wizard
Linear Regression with PyTorch About Linear Regression Simple Linear Regression Basics Allows us to understand relationship between two continuous variables Example x: independent variable y: dependent variable y = \alpha x + \beta Example of simple linear
www.deeplearningwizard.com
• list를 numpy array로 바꾸기
x_values = [ i for i in range(11) ]
x_train = np.array(x_values, dtype=np.float32)
•numpy array 형상 바꾸기
x_train.shape # (11, )
x_train = x_train.reshape(-1,1)
x_train.shape # (11, 1)
•Linear Regression 모델 만들기
import torch
import torch.nn as nn
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressinModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
•Instantiate Model Class
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
•Instantiate Loss Class
criterion = nn.MSELoss()
•Instantiate Optimizer Class
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameter(), lr=learning_rate)
• 모델로 학습시키기
* 1 epoch : x_train 데이터 전체를 한 번 도는 것
* 100 epochs : 100 * mapping of x_train = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
1) tensor의 gradient를 추적 가능한 상태로 만들기 : .requires_grad_()
2) gradient 0으로 리셋
3) 입력 데이터가 주어졌을 때, 모델이 예측한 값 얻기
4) 모델 예측값과 실제 정답을 비교해 오차 계산하기
5) 오차역전파로 gradient 구하기
6) gradient로 가중치 갱신하기
7) 반복
epochs = 100
for epoch in range(epochs):
epoch+=1 # 첫번째 epoch을 0이 아니라 1로 프린트하기 위해
# numpy array를 tensor로 바꾸고 gradient 추적 가능하게 설정
inputs = torch.from_numpy(x_train).requires_grad_()
labels = torch.from_numpy(y_train)
# gradient 0으로 리셋
optimizer.zero_grad()
# model에 입력 데이터 넣어 예측값 얻기
outputs = model(inputs)
# 오차 계산하기
loss = criterion(outputs, labels)
# gradient 구하기
loss.backward()
# 가중치 갱신
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
• 모델 저장하기
save_model = False
if save_model is True:
# parameter들만 저장함 (기울기, 편향)
torch.save(model.state_dict(), 'model_name.pkl')
• 모델 불러오기
load_model = False
if load_model is True:
model.load_state_dict(torch.load('model_name.pkl'))
3. Logistic Regression with PyTorch
https://www.deeplearningwizard.com/deep_learning/practical_pytorch/pytorch_logistic_regression/
Logistic Regression - Deep Learning Wizard
Logistic Regression with PyTorch About Logistic Regression Logistic Regression Basics Classification algorithm Example: Spam vs No Spam Input: Bunch of words Output: Probability spam or not Basic Comparison Linear regression Output: numeric value given inp
www.deeplearningwizard.com
Logistic Regression은 확률을 예측함
1) 2개의 class 구분
- Logistic Function (=sigmoid)
- Cross Entropy Function

2) 여러 개의 class 구분
- Softmax Function
- Cross Entropy Function
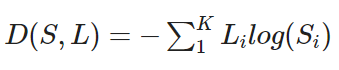
•MNIST train_data 불러오기
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as dsets
train_dataset = dsets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
• train_data 구조 확인
type(train_dataset[0]) # tuple
* ( image matrix, label ) 로 이루어진 튜플 형태
• train_data 크기 확인
# 첫 번째 데이터의 image matrix
train_dataset[0][0].size() # [1, 28, 28]
# 첫 번째 데이터의 label
train_dataset[0][1] # 5
•MNIST test_data 불러오기 (train_data와 같은 구조 : tuple (image, label)
test_dataset = dsets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
• 미니배치/반복/에폭 정의
- total data: 60000
- minibatch : 100 ( 한 번의 반복동안 학습하는 예시들의 개수)
- iterations : 3000 ( 1번 반복 = 1개의 mini-batch forward + backward pass)
- epochs : 5 ( 1 에폭 = 전체 데이터 한 번 돌리기)

batch_size = 100
n_iters = 3000
num_epochs = n_iters / (len(train_dataset) / batch_size)
num_epochs = int(num_epochs)
•Iterable Object 만들기 : train data
# Create Iterable Object
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# Check Iterability
import collections
isinstance(train_loader, collections.Iterable) # True
•Iterable Object 만들기 : test data
# Create Iterable Object
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# Check Iterability
isinstance(test_loader, collections.Iterable) # True
• 모델 만들기 (Linear Regression과 같음)
class LogisticRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LogisticRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
• Instantiate Model Class
input_dim = 28*28 # image size
output_dim = 10 # 0-9까지 10개 label 중 하나 선택
model = LogisticRegressionModel(input_dim, output_dim)
• Instantiate Loss Class
cf. Linear Regression의 오차는 MSE / Logistic Regression의 오차는 Cross Entropy
criterion = nn.CrossEntropyLoss()
• Instantiate Optimizer Class
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
• Parameters 자세히 살펴보기
model : y = AX + b
X : input data, size=28*28=784
A : coefficient, size=10*784
b : bias/intercept, size = 10*1
10*784 (행렬 곱) 784*1 = 10*1
10*1 (행렬 합) 10*1 = 10*1
따라서 ouput = 10*1 (각 10개의 label에 대한 확률)
len(list(model.parameters())) # 2 (A와 b)
list(model.parameters())[0].size() # A의 사이즈 : [10,784]
list(model.parameters())[1].size() # b의 사이즈 : [10]
• 모델 학습시키기
iter = 0
for epoch in range(num_epochs):
for i, (image, labels) in enumerate(train_loader):
images = image.view(-1, 28*28).requires_grad_()
labels = labels
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
iter+=1
if iter%500 == 0:
correct=0
total=0
for images, labels in test_loader:
images = image.view(-1, 28*28), requires_grad_()
# test에선 gradient로 학습하지 않으니 0으로 리셋하지 않아도 됨
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 최댓값의 index (여기선 index==label==0~9)
total+=labels.size(0)
correct+= (predicted == labels).sum()
accuracy = 100 * correct/total
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))
'nlp' 카테고리의 다른 글
| 딥러닝 모델 평가하기 (0) | 2020.02.04 |
|---|---|
| 1차원 배열 크기 주의 (0) | 2020.02.04 |
| [Learning PyTorch with Examples] 예시로 배우는 파이토치 정리 (0) | 2020.02.03 |
| [PyTorch Tutorials] 파이토치 튜터리얼 정리/번역 (0) | 2020.02.03 |
| 머신러닝은 즐거워~! part 1-8 메모 (0) | 2020.02.02 |