2019. 11. 4. 19:55ㆍnlp
넷플릭스와 네이버에서 203개 드라마, 932개 영화에 대한 시놉시스를 크롤링했다. 이제 각 시놉시스에 특정 품사가 얼마나 많이 쓰였는지 알아보려고 한다. PCA 분석도 하려면 다음과 같은 형식의 데이터를 만들어야 한다.
| 미디어 | 명사 | 동사 | ... | |
| 영화 제목1 | 네이버 | XXX | ZZZ | ... |
| 영화 제목2 | 넷플릭스 | YYY | III | ... |
우선 크롤링한 데이터에서 시놉시스에 해당되는 칼럼만 불러온다.

모든 시놉시스의 품사를 분석하기 전에 하나의 시놉시스만 분석해본다.
from konlpy.tag import Kkma
kkma = Kkma()
kkma.pos(df['desc'][0])
[('전도', 'NNG'), ('유망', 'NNG'), ('하', 'XSV'), ('ㄴ', 'ETD'), ('의과', 'NNG'), ('레지던트', 'NNG'), ('가', 'JKS'), ('어느', 'MDT'), ('날', 'NNG'), ('갑자기', 'MAG'), ('좀비', 'NNG'), ('가', 'JKC'), ('되', 'VV'), ('어', 'ECD'), ('생기', 'VV'), ('는', 'ETD'), ('이야기', 'NNG'), ('를', 'JKO'), ('그리', 'VV'), ('ㄴ', 'ETD'), ('드라마', 'NNG')]
그럼 이렇게 품사를 분석해주는데 우린 품사의 개수만 알면 된다. '전도'라는 단어가 'NNG'라는 품사로 분석되었다는 정보는 필요 없고, 전체 시놉시스에서 'NNG'로 분석된 품사가 몇 개인지만 알면 된다.
따라서 품사 분석 결과를 dictionary로 만들고 dict의 value만 취하면 된다.
dict(kkma.pos(df['desc'][0])).values()
dict_values(['NNG', 'NNG', 'XSV', 'ETD', 'NNG', 'NNG', 'JKC', 'MDT', 'NNG', 'MAG', 'NNG', 'VV', 'ECD', 'VV', 'ETD', 'NNG', 'JKO', 'VV', 'NNG'])
이제 이 value들의 빈도를 세면 된다. Counter를 이용하고 싶은데, Counter는 list에만 쓸 수 있으니 이 dict를 다시 list로 바꿔준다.
from collections import Counter
Counter(list(dict(kkma.pos(df['desc'][0])).values()))
Counter({'NNG': 8, 'XSV': 1, 'ETD': 2, 'JKC': 1, 'MDT': 1, 'MAG': 1, 'VV': 3, 'ECD': 1, 'JKO': 1})
드디어 우리가 원하는 정보가 나왔다. 이제 이 정보를 dataframe 형태로 바꿔주기만 하면 된다.
pd.DataFrame.from_dict(dict(Counter(list(dict(kkma.pos(df['desc'][0])).values()))), orient='index')
from_dict 함수를 이용하면 dict를 dataframe으로 변환할 수 있다.

근데 우리가 원하는 형태는 품사가 세로가 아니라 가로로 나열된 형태다. 그러면 transpose 함수를 쓰면 된다.
pd.DataFrame.from_dict(dict(Counter(list(dict(kkma.pos(df['desc'][0])).values()))), orient='index').transpose()
하나의 시놉시스에 대한 품사 분석을 dataframe 형태로 만들었다. 이제 for문을 돌려 2,000여개의 시놉시스 모두 품사 분석을 하자!
# 빈 데이터프레임 만들기
pos_df = pd.DataFrame()
# 시놉시스 개수만큼 for문 돌리기
for i in range(len(df['desc'])):
pos = pd.DataFrame.from_dict(dict(Counter(list(dict(kkma.pos(df['desc'][i])).values()))), orient='index').transpose()
# 이전 시놉시스 품사 분석 결과와 합치기
pos_df = pd.concat([pos_df,pos], axis=0, ignore_index=True)
# 이번 시놉시스에 등장하지 않은 품사의 값은 0으로
pos_df = pos_df.fillna(0)
이 코드의 결과로 나온 df는

이 데이터만으로는 어떤 영화의 품사 분석인지 알 수 없으니 기존 데이터의 일부와 합쳐준다.
df_factors = df[['title', 'desc', 'genre', 'media', 'len', 'sent_len']]
pos = pd.concat([df_factors,pos_df], axis=1)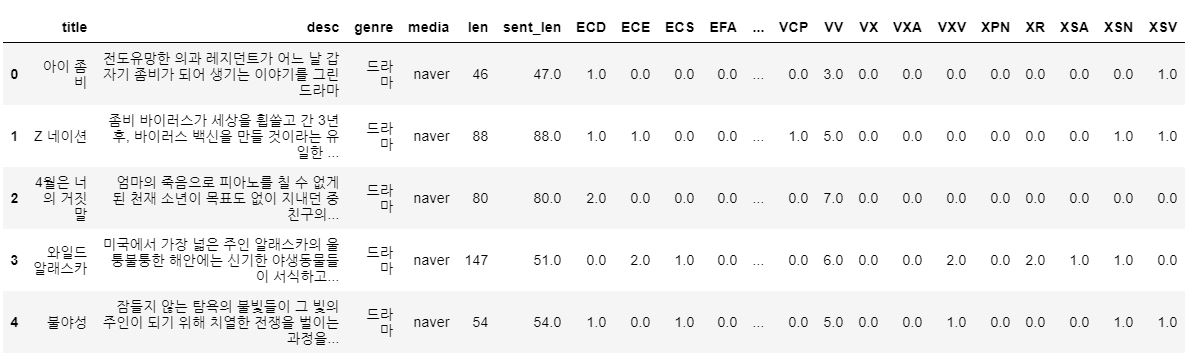
각 품사 태그(NNG, VV, XSV 등)의 의미는 여기를 참조하면 된다.
https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit
Korean POS tags comparison chart
chart Not provided in KoNLPy,Provided in KoNLPy Sejong project (ntags=42),Sim Gwangsub project (ntags=26),Twitter Korean Text (ntags=19),Komoran (ntags=42),Mecab-ko (ntags=43),Kkma (ntags=10),Kkma (ntags=30),Kkma (ntags=56),Hannanum (ntags=9),Hannanum (nta
docs.google.com
이제 품사 빈도를 표준화해준다. 네이버 시놉시스엔 일반명사가 10번, 넷플릭스엔 5번 쓰였다고 네이버가 무조건 일반명사를 많이 쓴다고 할 수 없다. 네이버 시놉시스의 길이가 더 길다면 말이다. 그래서 각 품사 빈도를 시놉시스 전체 길이로 나눠주려고 한다.
근데 그러면 값이 너무 작아져버린다. 한 시놉시스에 1번만 등장한 품사도 있는데 1을 전체 길이로 나눠버리면 0.000XX ... 엄청 작은 숫자가 된다. 그래서 이 값에 다시 1000을 곱해서 보기 쉽게 만들 것이다. 1000을 곱하면 '1000자당 특정 품사가 쓰인 빈도'라는 의미로 해석할 수 있게 된다.
위에서 만든 데이터를 df로 불러온 후 표준화를 한다.
# 모든 시놉시스에 대해
for i in range(len(df)):
# df.iloc[i,6:]은 품사 칼럼만 선택한 것 (제목, 미디어 등의 칼럼은 제외)
# df.iloc[i,4]은 len (시놉시스 전체 길이 칼럼)
df.iloc[i,6:] = df.iloc[i,6:].apply(lambda x : x/df.iloc[i,4])
생각해보니 시놉시스 전체를 계속 갖고 다닐 필요가 없어서 필요없어진 칼럼은 다 없애버렸다.
df = df.drop(columns=['desc', 'len', 'sent_len'])
그리고 이제 모든 [ 품사 빈도 / 전체 길이 ] 값에 1,000을 곱해준다.
for i in range(len(df)):
df.iloc[i,3:] = df.iloc[i,3:].apply(lambda x : 1000*x)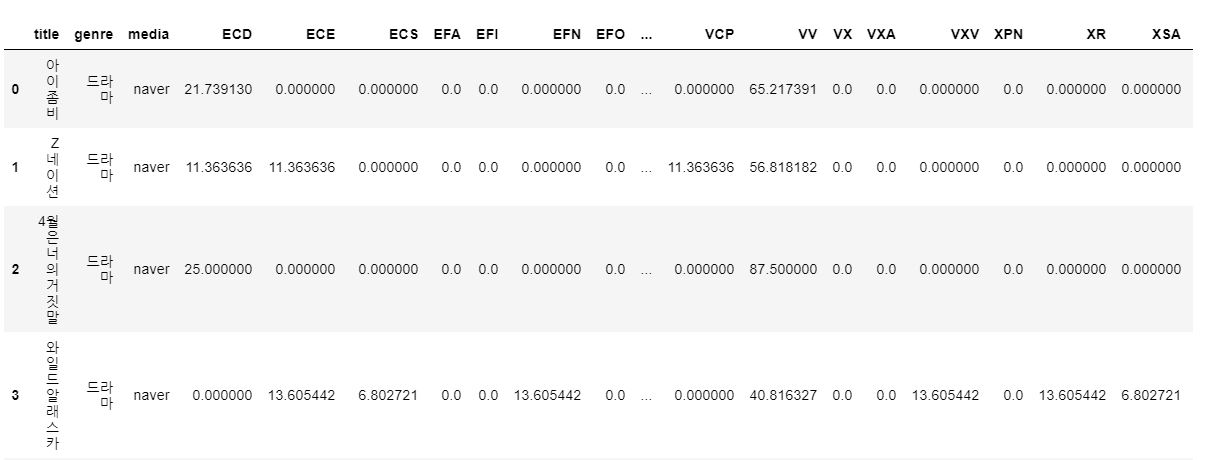
그럼 표준화까지 완료~!
'nlp' 카테고리의 다른 글
| 정규표현식 정리 (0) | 2019.12.04 |
|---|---|
| 넷플릭스/네이버 시놉시스 어휘 단계 분석하기 (0) | 2019.11.11 |
| 네이버 영화/드라마 시놉시스 크롤링 (6) | 2019.10.08 |
| '맴찢'의 품사는 무엇일까? (1) | 2019.10.05 |
| 하이킥 대본 후다닥 분석 (1) | 2019.10.04 |