2019. 12. 4. 13:36ㆍnlp
[ ] 괄호 안의 single character
[abc] : a 또는 b 또는 c
[ab]* : None 또는 aaaa 또는 abba
[0-9] : 숫자 = \d (반대는 [^0-9] = \D)
[A-Za-z] : 영어 대소문자 (아스키값은 대문자가 먼저)
[A-Za-z0-9_] : 영어 대소문자 + 숫자 + underscore(_) = \w (반대는 \W)
[\f\n\r\f\v] : 공백자들 = \s (반대는 \S)
^의 의미
1) \^ : 문자 그대로 ^
2) [ ] 맨 앞에서 부정의 의미 (ex) [^e] : e 빼고 아무나 한 글자 cf. [e^] : e 또는 ^ 한 글자
3) 스트링의 시작 (ex) ^a : a로 시작하는 스트링
스트링의 시작
1) ^the : 줄바꿈 단위로 하나의 스트링

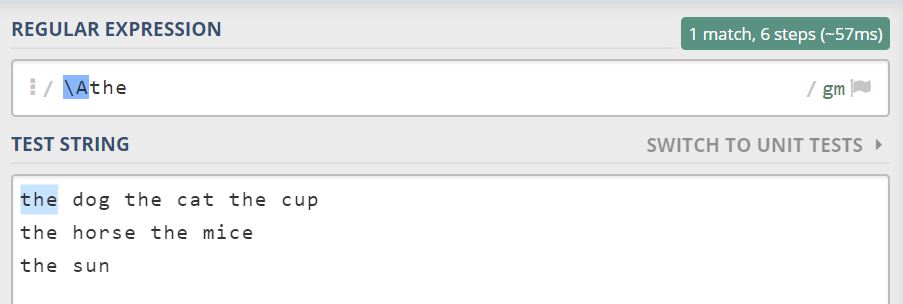
2) \Athe : 전체 글
3) \bthe : 공백 단위로 하나의 스트링

cf. \b의 반대는 \B
\Bthe : the는 the인데 the 앞에 뭔가 붙어있어야 찾아줌

\Bthe\B : the는 the인데 the 앞뒤로 뭔가 붙어있어야 찾아줌

정규표현식 확인은 여기서
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
Please wait while the app is loading...
regex101.com
스트링의 끝
a$ : a로 끝나는 스트링 찾아줌 (줄바꿈 단위)
. any single character
반복
1) * : 0번~무한대 반복 (ex) n\d* = n, n1, n12, ...
2) + : 1번~무한대 반복
3) ? : 0번 또는 1번 등장 (ex) apples? = apple 또는 apple
cf. ? 는 non-greedy search의 의미도 있음
string = <div> simple </div>
pattern = <.+> 이면 <div> simple </div>
pattern = <.+?> 이면 <div>
4) { } : 횟수 지정 (ex) a{3,5} : a가 3번~5번 반복
| 또는
(cat|dog) : cat 또는 dog를 찾아줌 (ex) gupp(y|ies) = guppy 또는 guppies
cf. [catdog] : c,a,t,d,o,g 한 문자 각각을 찾아줌
\ escape : 원래 기능 상실
d(?=r) : d는 d인데 바로 뒤에 r이 오는 d
(?<=r)d : d는 d인데 바로 앞에 r이 오는 d
둘의 반대는 = 를 ! 로 바꾼 것
d(?!r) : d는 d인데 바로 뒤에 r이 안 오는 d
(?<!r)d : d는 d인데 바로 앞에 r이 안 오는 d
( )
1) 우선순위
2) 캡쳐 : 첫 번째 괄호는 \1, 두 번째 괄호는 \2, ... 전체는 \0 (ex) (to)ma\1 = tomato
파이썬에서 정규표현식 쓰기
import re
re.findall
re.split
re.sub, re.subn
re.search
import re
string = "This is a <div> simple div </div> test"
pattern = "<.+?>"
# 정규표현에 해당되는 부분 모두 찾기
re.findall(pattern, string)
# 정규표현 찾아 그 표현 기준으로 split
re.split(pattern, string)
# 몇 번 split할 지 명시 가능
# 1번만 나눠라
re.split(pattern, string, 1)
# 정규표현 찾아 새로운 문구로 바꿔라
replace=''
re.sub(pattern, replace, string)
# 몇 번 바꿀건지 명시 가능
re.sub(pattern, replace, string, 1)
# 몇 번 바꿨는지도 물어보기
re.subn(pattern, replace, string)
match = re.search(pattern, string)
if match :
print(match.group())
# match.group(1) 또는 match.group(1,2) 또는 match.groups()
# index 반환 : match.start() 또는 match.end() 또는 match.span()
else:
print("not found")
'nlp' 카테고리의 다른 글
| Language Modeling (0) | 2019.12.04 |
|---|---|
| Minimum Edit Distance (0) | 2019.12.04 |
| 넷플릭스/네이버 시놉시스 어휘 단계 분석하기 (0) | 2019.11.11 |
| 넷플릭스/네이버 시놉시스 품사 분석하기 (3) | 2019.11.04 |
| 네이버 영화/드라마 시놉시스 크롤링 (6) | 2019.10.08 |