2020. 2. 4. 18:44ㆍnlp
Feedforward Neural Networks (FNN) - Deep Learning Wizard
Feedforward Neural Network with PyTorch About Feedforward Neural Network Logistic Regression Transition to Neural Networks Logistic Regression Review Define logistic regression model Import our relevant torch modules. import torch import torch.nn as nn Def
www.deeplearningwizard.com
비선형 함수
1) Sigmoid (Logistic)
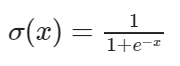
- 출력 : [0,1]
- (단점) 출력값이 0이나 1에 가까우면 gradients는 거의 0에 수렴 → 가중치 갱신/학습 불가
- (해결) 가중치 초기화를 조심히! 신경써서
2) Tanh
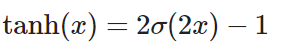
- 출력 : [-1, 1]
- (단점) 출력값이 0이나 1에 가까우면 gradients는 거의 0에 수렴 → 가중치 갱신/학습 불가
- (해결) 가중치 초기화를 조심히! 신경써서
3) ReLU (Rectified Linear Units)

- 학습 빠름
- (단점) gradient = 0 인 구간이 많음 (음수인 구간)
- (해결) learning rate를 조심히! 신경써서
Model A : 1 Hidden Layer Feedforward Neural Network (Sigmoid Activation)
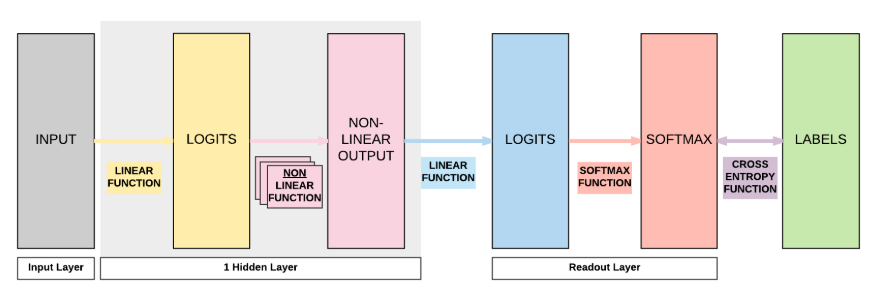
1) MNIST train data 불러오기 → 지난 글과 같은 방법
2) Dataset 반복 가능하게(iterable) 만들기 → 지난 글과 같은 방법
3) Model Class 만들기
class FeedforwardNeuralNetModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(FeedforwardNeuralNetModel, self).__init__()
# Linear Function
self.fc1 = nn.Linear(input_dim, hidden_dim)
# Non-Linearity
self.sigmoid = nn.Sigmoid()
# Linear function (readout)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# Linear function
out = self.fc1(x)
# Non-Linearity
out = self.sigmoid(out)
# Linear function (readout)
out = self.fc2(out)
return out
4) Instantiate Model Class
- Input size = 28*28 (image size)
- Output size = 10 (0-9 중 하나 고르기)
- Hidden size = 100 (아무 숫자나 가능)
- hidden size = number of neurons = number of non-linear activation functions
- non-linear layers 는 parameter를 갖고 있지 않음. 그냥 Y 값에 계산되는 수학적 함수일 뿐
input_dim = 28*28
hidden_dim = 100
output_dim = 10
model = FeedforwardNeuralNetModel(input_dim, hidden_dim, output_dim)
5) Instatiate Loss Class
- 0-9 분류 문제를 수행하기 때문에 Logistic Regression과 똑같이 오차 함수로 Cross Entropy Loss를 사용함
criterion = nn.CrossEntropyLoss()
6) Instatiate Optimizer Class
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
Parameters 자세히 살펴보기
• len(list(model.parameters())) # 4
2개의 Linear Function이 각각 A, b라는 2개의 parameter를 갖고 있기 때문
• list(model.parameters())[0].size() # 100*784
FC1 layer (첫번째 Linear Function) 의 A 사이즈
input size는 784(=28*28), hidden size는 100이므로
• list(model.parameters())[1].size() #100
FC1 layer (첫번째 Linear Function) 의 b 사이즈
hidden size가 100이므로
• list(model.parameters())[2].size() # 10*100
FC2 layer (두번째 Linear Function) 의 A 사이즈
output size는 10, hidden size는 100이므로
• list(model.parameters())[3].size() # 10
FC2 layer (두번째 Linear Function) 의 b 사이즈
output size는 10이므로

7) Train Model
iter = 0
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Load images with gradient accumulation capabilities
images = images.view(-1, 28*28).requires_grad_()
# Clear gradients w.r.t. parameters
optimizer.zero_grad()
# Forward pass to get output/logits
outputs = model(images)
# Calculate Loss: softmax --> cross entropy loss
loss = criterion(outputs, labels)
# Getting gradients w.r.t. parameters
loss.backward()
# Updating parameters
optimizer.step()
iter += 1
if iter % 500 == 0:
# Calculate Accuracy
correct = 0
total = 0
# Iterate through test dataset
for images, labels in test_loader:
# Load images with gradient accumulation capabilities
images = images.view(-1, 28*28).requires_grad_()
# Forward pass only to get logits/output
outputs = model(images)
# Get predictions from the maximum value
_, predicted = torch.max(outputs.data, 1)
# Total number of labels
total += labels.size(0)
# Total correct predictions
correct += (predicted == labels).sum()
accuracy = 100 * correct / total
# Print Loss
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))
Model B : 1 Hidden Layer Feedforward Neural Network (Tanh Activation)
self.sigmoid = nn.Sigmoid() → self.tanh = nn.Tanh() 으로 수정
out = self.sigmoid(out) → out = self.tanh(out) 으로 수정
이 외에는 Model A와 모두 동일
Model C : 1 Hidden Layer Feedforward Neural Network (ReLU Activation)
self.relu = nn.ReLU()
out = self.relu(out)
이 외에는 Model A와 모두 동일
Model D : 2 Hidden Layer Feedforward Neural Network (ReLU Activation)

class FeedforwardNeuralNetModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(FeedforwardNeuralNetModel, self).__init__()
# Linear Function 1 : 784 -> 100
self.fc1 = nn.Linear(input_dim, hidden_dim)
# Non-Linear 1
self.relu1 = nn.ReLU()
# Linear Function 2 : 100 -> 100
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
# Non-Linear 2
self.relu2 = nn.ReLU()
# Linear Function 3 (readout) : 100 -> 10
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# Linear 1
out = self.fc1(x)
# Non-Linear 1
out = self.relu1(out)
# Linear 2
out = self.fc2(out)
# Non-Linear 2
out = self.relu2(out)
# Linear 3 (readout)
out = self.fc3(out)
return out
<결론>
Neural Network 확장하기
1) hidden layers 더 많이 쌓기 (Non-Linear 함수 추가)
2) hidden_size 늘리기 (non-linear activation units/neurons 늘리기)
'nlp' 카테고리의 다른 글
| [Hyper-parameter Tuning] 하이퍼 파라미터 튜닝 (0) | 2020.02.05 |
|---|---|
| [DL Wizard] Forwardpropagation, Backpropagation and Gradient Descent with PyTorch 번역 및 정리 (0) | 2020.02.04 |
| 딥러닝 모델 평가하기 (0) | 2020.02.04 |
| 1차원 배열 크기 주의 (0) | 2020.02.04 |
| [DL Wizard] Matrices/Linear Regression/Logistic Regression with PyTorch 번역 및 정리 (0) | 2020.02.04 |