2020. 2. 11. 15:46ㆍnlp
http://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), Persian The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natu
jalammar.github.io
BERT (=Bidirectional Encoder Representations from Transformers)
- 학습된 여러 Transformer Encoder들
- 두 종류 (1) BERT_BASE (2) BERT_LARGE (크기 차이)

Model Inputs
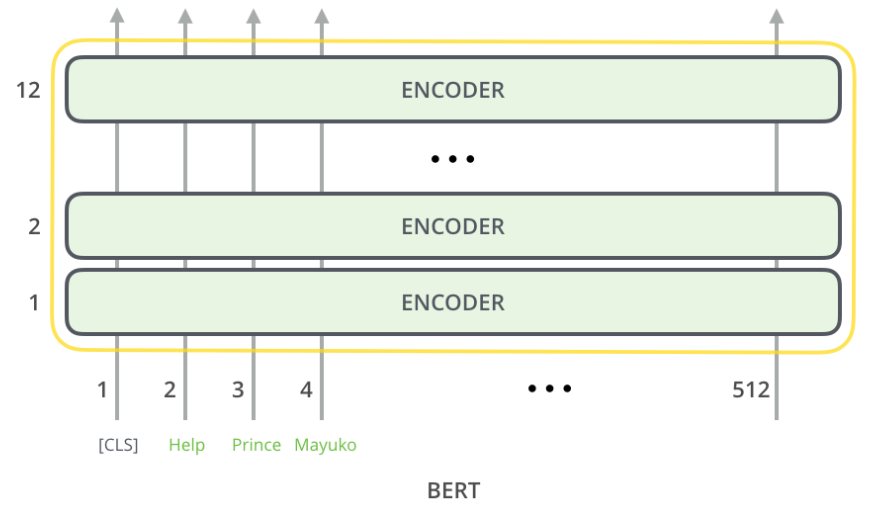
Model Outputs
- [CLS] 토큰의 BERT output은 Classifier를 거쳐 각 class에 속할 확률을 알려줌

기존 Word Embedding
- 그 단어가 어떤 문맥에 있든 상관없이 항상 같은 embedding 값을 사용함
ELMo : 문맥을 고려한 임베딩
- 문맥에 따라 같은 단어라도 embedding 값이 달라짐
- Language Modeling 덕에 가능 : ELMo는 단어의 연쇄를 받으면 그 다음 단어를 예측하도록 훈련받음

- Bidirectional LSTM을 사용 : 이전 단어뿐만 아니라 다음 단어도 고려한 embedding

OpenAI Transformer : Language Modeling
- Language Modeling을 위해 Transformer Decoder를 사용함
- 기존 Transformer에 있던 Decoder와 달리, encoder-decoder attention layer는 사라짐 (Encoder가 없으니까)
- 기존 Transformer에 있던 Decoder와 똑같이, self-attention layer는 여전히 있음 (현재 시점 이후_미래의_토큰은 masked)

OpenAI Transformer : Classification
- Language Modeling으로 Pre-trained된 OpenAI Transformer를 분류 과제에 사용

- 하지만 ELMo의 Language Modeling은 bi-directional이었음. OpenAI Transformer는 forward Language Model
- BERT는 Transformer의 Encoder를 사용해 이 문제를 해결
BERT : Masked Language Model
- 마스크mask를 사용
- 마스크로 가려진 단어의 위치에 나온 output을 이용해 마스크로 가려진 단어를 예측함

- BERT는 두 문장의 관계를 학습하기도 함. 문장 B가 문장 A 다음에 오는가?

- 다양한 과제를 수행하는 BERT

BERT : Feature Extraction
- BERT를 이용해 문맥을 고려한 word embedding을 얻을 수 있다
- 이 embedding을 기존 모델에 넣어줄 수 있다
- 각 Encoder의 output을 모두 그 단어의 embedding으로 사용할 수 있다
- 문제는? 어떤 layer의 output이 가장 좋은 embedding인가?!


'nlp' 카테고리의 다른 글
| BERT Word Embeddings 튜토리얼 번역 및 정리 (3) | 2020.02.14 |
|---|---|
| BERT 파헤치기 Part 1-2 번역 및 정리 (0) | 2020.02.11 |
| Seq2seq pay Attention to Self Attention Part 1-2 번역 및 정리 (0) | 2020.02.10 |
| 그림으로 보는 Transformer 번역 및 정리 (0) | 2020.02.10 |
| [seq2seq + Attention] 불어-영어 번역 모델 PyTorch로 구현하기 (0) | 2020.02.10 |