2020. 2. 5. 17:17ㆍnlp
https://www.deeplearningwizard.com/deep_learning/boosting_models_pytorch/lr_scheduling/
Learning Rate Scheduling - Deep Learning Wizard
Learning Rate Scheduling Optimization Algorithm: Mini-batch Stochastic Gradient Descent (SGD) We will be using mini-batch gradient descent in all our examples here when scheduling our learning rate Combination of batch gradient descent & stochastic gradien
www.deeplearningwizard.com
2가지 Learning Rate Schedules
1) Step-wise Decay
2) Reduce on Loss Plateau Decay
Step-wise Decay
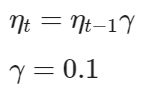
- 이전 학습률 * gamma = 다음 학습률
- 2개의 하이퍼 파라미터 : step_size, gamma
...
from torch.optim.lr_scheduler import StepLR
...
# Instantiate optimizer class
learning_rate = 0.1
oprimizer = torch.opim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, nesterov=True)
# Instantiate step learning scheduler class
# step_size: at how many multiples of epoch you decay
# step_size = 1, after every 1 epoch, new_lr = lr*gamma
# step_size = 2, after every 2 epoch, new_lr = lr*gamma
# gamma = decaying factor
scheduler = StepLR(optimizer, step_size=1, gamma=0.1)
# Train the model
iter=0
for epoch in range(num_epochs):
# Decay learning rate
scheduler.step()
# Print learning rate
print('Epoch:', epoch,'LR:', scheduler.get_lr())
for i, (images, labels) in enumerate(train_loader):
images = images.view(-1, 28*28).requires_grad_()
# Clear gradients
optimizer.zero_grad()
# Forward pass to get output
outputs = model(images)
# Calculate Loss : softmax --> cross entropy loss
loss = criterion(outputs, labels)
# Get gradients
loss.backward()
# Update parameters
optimizer.step()
iter+=1
...
Reduce on Loss Plateau Decay
- 오차가 더 이상 줄어들지 않고 같은 값에 머물면 학습률 줄이기
* plateau (verb) to reach a state or level of little or no growth or decline, especially to stop increasing or progressing
- Patience : 오차가 줄어들지 않기 시작한 후 몇 번의 epoch부터 학습률을 줄일지
- epoch이 크면 patience도 더 크게 설정하기
- 2개의 하이퍼 파라미터 : patience, decay factor
...
from torch.optim.lr_scheduler import ReduceLROnPlateau
...
# Instantiate Optimizer Class
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, nesterov=True)
# Instantiate Step Learning Scheduler Class
# lr = lr * factor
# mode='max': look for the maximum validation accuracy to track
# patience: number of epochs - 1 where loss plateaus before decreasing LR
# patience = 0, after 1 bad epoch, reduce LR
# factor = decaying factor
scheduler = ReduceLROnPlateau(optimizer, mode='max', factor=0.1, patience=0, verbose=True)
...
'nlp' 카테고리의 다른 글
| [DL Wizard] Weight Initializations & Activation Functions 번역 및 정리 (0) | 2020.02.05 |
|---|---|
| [DL Wizard] Optimization Algorithms 번역 및 정리 (0) | 2020.02.05 |
| [DL Wizard] Derivative, Gradient and Jacobian 번역 및 정리 (0) | 2020.02.05 |
| [Hyper-parameter Tuning] 하이퍼 파라미터 튜닝 (0) | 2020.02.05 |
| [DL Wizard] Forwardpropagation, Backpropagation and Gradient Descent with PyTorch 번역 및 정리 (0) | 2020.02.04 |