2020. 2. 5. 22:18ㆍnlp
Weight Initialization and Activation Functions - Deep Learning Wizard
Weight Initializations & Activation Functions Recap of Logistic Regression Recap of Feedforward Neural Network Activation Function Sigmoid (Logistic) \sigma(x) = \frac{1}{1 + e^{-x}} Input number \rightarrow [0, 1] Large negative number \rightarrow 0 Large
www.deeplearningwizard.com



Weight Initialization & Activation Functions의 필요성
기울기 소실/폭발vanishing/exploding gradients 을 방지하기 위해
1) Sigmoid/Tanh
<문제>
- 입력 데이터의 분산이 너무 크면 : gradients = 0 (기울기 소실)
- 입력 데이터의 분산이 너무 작으면 : 거의 선형 함수가 됨 (gradients = 일정한 값)
<해결>
- 입력 데이터의 분산을 일정하게 유지 → gradients 값이 모두 달라서 갱신이 잘 이루어짐
- Xavier 초깃값 사용하여 분산 유지
- ReLU 또는 Leaky ReLU 사용 (입력 데이터의 분산에 상관없이 항상 gradients 값은 0 또는 1)
2) ReLU
<문제>
- gradients = 0 인 경우 갱신이 이루어지지 않음 ("dead ReLU units")
- 출력값이 무한대로 큼 → 기울기 폭발 가능
<해결>
- He 초깃값 사용 (입력 데이터의 분산 일정하게 유지)
- Leaky ReLU (입력이 음수라도 gradients!=0)
3) Leaky ReLU

<문제>
- 출력값이 무한대로 큼 → 기울기 폭발 가능
<해결>
- He 초깃값 사용 (입력 데이터의 분산 일정하게 유지)
Weight Initialization의 유형
1) Zero Initialization : 모든 가중치를 0으로 설정
- 모든 뉴런이 같은 출력, 같은 gradient를 계산해 똑같이 갱신됨
2) Normal Initialization : 모든 가중치를 랜덤한 작은 수치로 설정
- 모든 뉴런이 다른 출력, 다른 gradient를 계산해 다른 값으로 갱신됨
- 입력 데이터가 많을수록 분산이 커짐
3) Lecun Initialization : 분산 정규화
- 분산 커지는 것 방지 → 분산을 일정하게 유지 Var(y) = Var(x_i)

- Var(a_i) = 1/n (* 가중치들의 분산이 1/n)
- 가중치들의 평균=0, 분산=1/n
4) Xavier 초깃값
- sigmoid가 활성화 함수일 때 좋음

- n_in = 가중치 텐서에서 입력 데이터의 개수
- n_out = 가중치 텐서에서 출력 데이터의 개수
5) He 초깃값 (=Kaiming Initialization)
- ReLU 또는 Leaky ReLU가 활성화 함수일 때 좋음
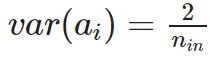
Weight Initialization with PyTorch
2) Normal Initialization
nn.init.normal_(self.fc1.weight, mean=0, std=1)
nn.init.normal_(self.fc2.weight, mean=0, std=1)
class FeedforwardNeuralNetModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(FeedforwardNeuralNetModel, self).__init__()
# Linear function
self.fc1 = nn.Linear(input_dim, hidden_dim)
# Linear weight, W 초기화 (Y=WX+B)
nn.init.normal_(self.fc1.weight, mean=0, std=1)
# Non-Linear
self.tanh = nn.Tanh()
# Linear function (readout)
self.fc2 = nn.Linear(hidden_dim, output_dim)
nn.init.normal_(self.fc2.weight, mean=0, std=1)
...
3) Lecun Initialization
PyTorch는 디폴트로 Lecun Initialization 사용. 그냥 layer 만들면 자동으로 Lecun 초기화
4) Xavier 초깃값
nn.init.xavier_normal_(self.fc1.weight)
nn.init.xavier_normal_(self.fc2.weight)
class FeedforwardNeuralNetModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(FeedforwardNeuralNetModel, self).__init__()
# Linear function
self.fc1 = nn.Linear(input_dim, hidden_dim)
# Linear weight, W, Y = WX + B
nn.init.xavier_normal_(self.fc1.weight)
# Non-linearity
self.tanh = nn.Tanh()
# Linear function (readout)
self.fc2 = nn.Linear(hidden_dim, output_dim)
nn.init.xavier_normal_(self.fc2.weight)
...
5) He 초깃값
nn.init.kaiming_normal_(self.fc1.weight)
nn.init.kaiming_normal_(self.fc2.weight)
'nlp' 카테고리의 다른 글
| CNN for NLP 번역 및 정리 (0) | 2020.02.06 |
|---|---|
| CNN : Convolutional Neural Network 정리 (0) | 2020.02.06 |
| [DL Wizard] Optimization Algorithms 번역 및 정리 (0) | 2020.02.05 |
| [DL Wizard] Learning Rate Scheduling 번역 및 정리 (0) | 2020.02.05 |
| [DL Wizard] Derivative, Gradient and Jacobian 번역 및 정리 (0) | 2020.02.05 |