2020. 2. 9. 00:15ㆍnlp
bentrevett/pytorch-seq2seq
Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and TorchText. - bentrevett/pytorch-seq2seq
github.com
독일어를 영어로 번역하는 모델 PyTorch로 구현하기
- Encoder-Decoder LSTM(=seq2seq) 모델은 RNN을 이용해 input을 feature vector로 인코딩함
- 이렇게 인코딩된 vector를 여기선 'context vector'라 부르기로 함
- 'context vector' : input 문장(독일어 문장)의 추상적인/압축된 representation
- 이 context vector는 두 번째 RNN을 통해 디코딩되어 영어 문장을 생성함
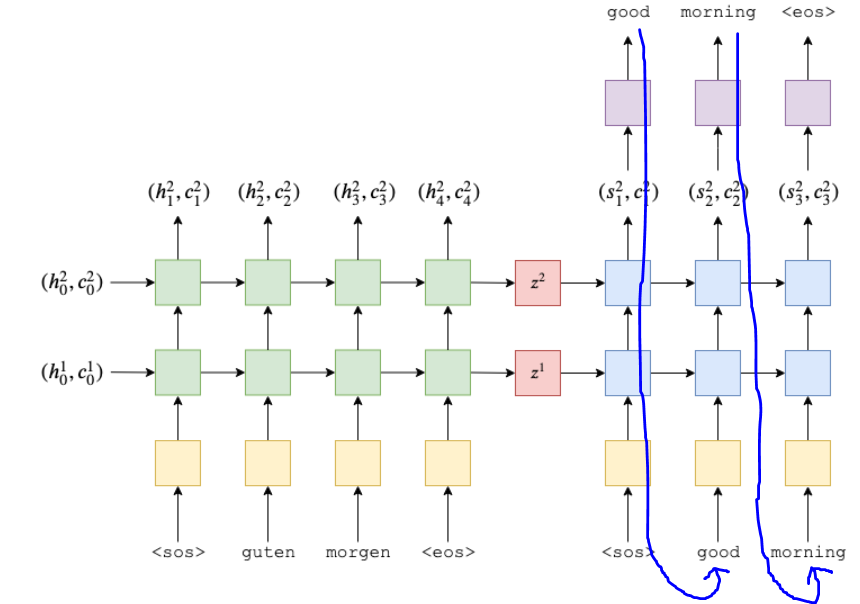

- EncoderRNN은 입력 문장 각 단어(<sos>, guten 등)의 임베딩과 전 단계의 은닉상태를 받아 다음 은닉상태를 출력함
- guten, morgen 등이 노란 박스(embedding layer, e)를 거쳐 embedding으로 변환됨
- EnoderRNN의 마지막 은닉상태(최종 출력) = context vector = z
- RNN 대신 LSTM, GRU 등 뭐든 올 수 있음

- z = s0 = context vector
- DecoderRNN의 첫 은닉상태는 context vector
- good, morning 등이 노란 박스(embedding layer, d)를 거쳐 embedding으로 변환됨
* 독일어의 embedding layer와 영어의 embedding layer는 서로 다른 파라미터를 가진 다른 레이어
- DecoderRNN은 각 time-stamp마다 현재 단어인 d(y_t)의 임베딩 + 이전 time-stamp의 은닉상태인 s_(t-1)을 입력 받음

- 은닉 상태(s1, s2, s3)를 실제 단어로 디코딩하기
- 각 time-stamp마다 은닉상태를 Linear layer(보라색 박스)에 넣어 실제 단어를 예측함
- 학습할 땐 target sentence의 길이를 명확히 알 수 있지만 추론할 땐 문장이 언제 끝날지 모름. <eos> 태그 나올때 까지 계속 생성함
- 학습 후 예측한 문장과 정답 문장 비교해 오차 구함. 이를 통해 파라미터 갱신
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
Tokenizer Model 불러오기
(설치 방법)
python -m spacy download en
python -m spacy download de
# 각 언어에 맞는 tokenizer 불러오기
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
쓸 수 있는 tokenizer 함수 만들기
def tokenize_de(text):
# 독일어 tokenize해서 단어들을 리스트로 만든 후 reverse
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
# 영어 tokenize해서 단어들을 리스트로 만들기
return [tok.text for tok in spacy_en.tokenizer(text)]
TorchText의 Field : 데이터가 어떻게 처리되어야 하는지 정할 수 있음
# SRC = source = input
SRC = Field(tokenize = tokenize_de, init_token='<sos>', eos_token='<eos>', lower=True)
# TRG = target = output
TRG = Field(tokenize = tokenize_en, init_token='<sos>', eos_token='<eos>', lower=True)
Multi30k 데이터 불러오기 (영어에 해당하는 독일어/불어 문장들이 있음)
# exts : 어떤 언어 사용할지 명시 (input 언어를 먼저 씀)
# fields = (입력, 출력)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC,TRG))
데이터 확인
print(vars(train_data.examples[0]))
→ {'src': ['.', 'büsche', 'vieler', 'nähe', 'der', 'in', 'freien', 'im', 'sind', 'männer', 'weiße', 'junge', 'zwei'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']}
→ 독일어는 단어 순서가 거꾸로
Vocab Building
- 각 unique 토큰을 index에 대응시키기
- 독일어의 vocab과 영어의 vocab은 다름
- min_freq=2 : 2번 이상 등장하는 단어만 vocab에 포함시키기. 한번만 나오는 단어는 <unk> 토큰으로 처리
* <unk> = unknown
- vocab은 training set에서만 만들어져야 함 (validation/test set에서 만들면 안 됨)
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
Iterator 만들기
batch_size = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(train_data, valid_data, test_data), batch_size=batch_size)
Seq2seq Model 만들기
1) Encoder
2 layer RNN

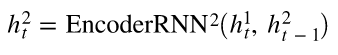
- Layer 1 : 독일어 토큰의 임베딩을 입력으로 받고 은닉상태 출력
- Layer 2 : Layer 1의 은닉상태를 입력으로 받고 새로운 은닉상태 출력
- 각 layer마다 초기 은닉상태 h_0이 필요
- 각 layer마다 context vector 'z'를 출력함
RNN vs LSTM
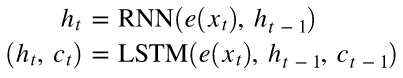
- LSTM은 cell state, c 도 필요함
- c_0 과 h_0 모두 0으로 초기화됨
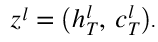
- LSTM이 출력한 context vector (마지막 은닉상태와 마지막 cell state)
2 layer LSTM
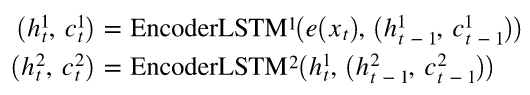

class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self. hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src = [src len, batch_size]
embedded = self.dropout(self.embedding(src))
# embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
# outputs = [src len, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
return hidden, cell
• input_dim = input 데이터의 vocab size = one-hot vector의 사이즈
* 단어들의 index가 embedding 함수로 넘겨짐
•emb_dim = embedding layer의 차원
* embedding 함수 : one-hot vector를 emb_dim 길이의 dense vector로 변환
• hid_dim = 은닉 상태의 차원 ( = cell state의 차원)
• n_layers = RNN 안의 레이어 개수 (여기선 2개)
•dropout = 사용할 드롭아웃의 양 (오버피팅 방지하는 정규화 방법)
•n_directions = 1
cf. bidirectional RNN의 경우 : n_directions=2
- 초기 은닉 상태, cell state 명시해주지 않으면, 디폴트로 모두 0으로 채워진 텐서로 초기화
- outputs : 맨 위 레이어에서 각 time-stamp마다의 은닉 상태들
- hidden : 각 레이어의 마지막 은닉상태, h_T
- cell : 각 레이어의 마지막 cell state, c_T
1) Decoder
2 Layer LSTM
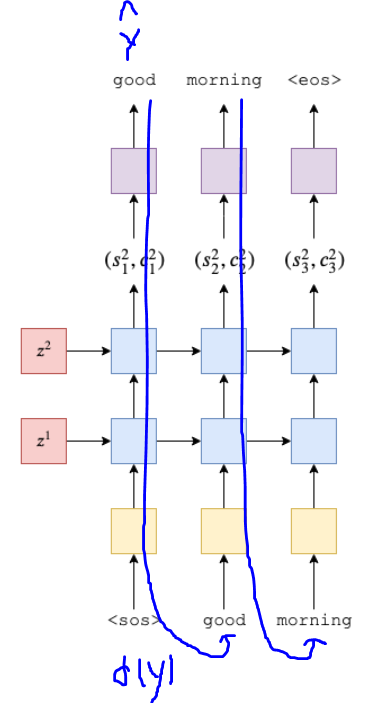
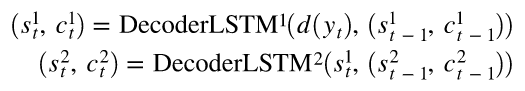
Layer 1 : 직전 time-stamp로부터 은닉 상태(s)와 cell state를 받고, 이들과 embedded token인 y_t 를 입력으로 받아 새로운 은닉상태와 cell state를 만들어냄
Layer 2 : Layer 1의 은닉 상태(s)와 Layer 2에서 직전 time-stamp의 은닉 상태(s)와 cell state를 입력으로 받아 새로운 은닉 상태와 cell state를 만들어냄
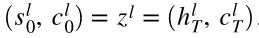
Decoder Layer1의 첫 은닉상태(s)와 cell state = context vector (z) = Encoder Layer 1의 마지막 은닉상태(h)와 cell state

Decoder RNN/LSTM의 맨 위 Layer의 은닉 상태를 Linear Layer인 f에 넘겨서 다음 토큰이 무엇일지 예측함
y_hat 은 Decoder가 예측한 단어 (ex) "good", "morning" 등
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout_
def forward(self, input, hidden, cell):
# input = [batch size]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# Decoder에서 항상 n directions = 1
# 따라서 hidden = [n layers, batch size, hid dim]
# context = [n layers, batch size, hid dim]
# input = [1, batch size]
input = input.unsqueeze(0)
# embedded = [1, batch size, emb dim]
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output = [seq len, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# Decoder에서 항상 seq len = n directions = 1
# 한 번에 한 토큰씩만 디코딩하므로 seq len = 1
# 따라서 output = [1, batch size, hid dim]
# hidden = [n layers, batch size, hid dim]
# cell = [n layers, batch size, hid dim]
# prediction = [batch size, output dim]
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden, cell
•output_dim = output 데이터의 vocab size
cf. input_dim은 데이터에서 주어진대로, output_dim은 우리가 직접 정해서 초기화
•hidden, cell은 각 time-stamp/각 레이어들의 은닉상태와 cell state들의 리스트
• output은 마지막 time-stamp/마지막 레이어의 은닉상태만
• input = [batch size] → unsqueeze → input = [1, batch size]
• input = [1, batch size] → embedding → dropout → embedded = [1, batch size, emb dim]
•embedded, hidden, cell → rnn → output, hidden, cell
•output = [1, batch size, hid dim] → squeeze → output = [batch size, hid dim]
•output = [batch size, hid dim] → fc_out → prediction = [batch size, output dim]
Seq2seq
Build Model
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
# Encoder와 Decoder의 hidden dim이 같아야 함
assert encoder.hid_dim == decoder.hid_dim
# Encoder와 Decoder의 layer 개수가 같아야 함
assert encoder.n_layers == decoder.n_layers
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [src len, batch size]
# trg = [trg len, batch size]
trg_len = trg.shape[0]
batch_size = trg.shape[1]
trg_vocab_size = self.decoder.ouput_dim
# decoder 결과를 저장할 텐서
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size)
# Encoder의 마지막 은닉 상태가 Decoder의 초기 은닉상태로 쓰임
hidden, cell = self.encoder(src)
# Decoder에 들어갈 첫 input은 <sos> 토큰
input = trg[0, :]
# target length만큼 반복
# range(0,trg_len)이 아니라 range(1,trg_len)인 이유 : 0번째 trg는 항상 <sos>라서 그에 대한 output도 항상 0
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output
# random.random() : [0,1] 사이 랜덤한 숫자
# 랜덤 숫자가 teacher_forcing_ratio보다 작으면 True니까 teacher_force=1
teacher_force = random.random() < teacher_forcing_ratio
# 확률 가장 높게 예측한 토큰
top1 = output.argmax(1)
# techer_force = 1 = True이면 trg[t]를 아니면 top1을 input으로 사용
input = trg[t] if teacher_force else top1
return outputs
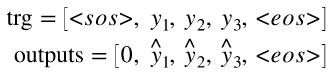
Instantiate Model
input_dim = len(SRC.vocab)
output_dim = len(TRG.vocab)
# Encoder embedding dim
enc_emb_dim = 256
# Decoder embedding dim
dec_emb_dim = 256
hid_dim=512
n_layers=2
enc_dropout = 0.5
dec_dropout=0.5
enc = Encoder(input_dim, enc_emb_dim, hid_dim, n_layers, enc_dropout)
dec = Decoder(output_dim, dec_emb_dim, hid_dim, n_layer, dec_dropout)
model = Seq2Seq(enc, dec, device)
가중치 초기화
(-0.08, 0.08) 범위의 정규분포에서 모든 가중치를 초기화
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uiform_(param.data, -0.08, 0.08)
model.apply(init_weights)
Optimizer / Loss
optimizer = optim.Adam(model.parameters())
# <pad> 토큰의 index를 넘겨 받으면 오차 계산하지 않고 ignore하기
# <pad> = padding
trg_pad_idx = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = trg_pad_idx)
Train Model
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss=0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
# trg = [trg len, batch size]
# output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
# loss 함수는 2d input으로만 계산 가능
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
# trg = [(trg len-1) * batch size]
# output = [(trg len-1) * batch size, output dim)]
loss = criterion(output, trg)
loss.backward()
# 기울기 폭발 막기 위해 clip
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss+=loss.item()
return epoch_loss/len(iterator)
Test Model
def evaluate(model, iterator, criterion):
model.eval()
eopch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
# teacher_forcing_ratio = 0 (아무것도 알려주면 안 됨)
output = model(src, trg, 0)
# trg = [trg len, batch size]
# output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
# trg = [(trg len - 1) * batch size]
# output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss+=loss.item()
return epoch_loss/len(iterator)
성능 가장 좋았던 모델 저장하기
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
성능 가장 좋았던 모델 불러오기
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')'nlp' 카테고리의 다른 글
| [seq2seq + Attention] 불어-영어 번역 모델 PyTorch로 구현하기 (0) | 2020.02.10 |
|---|---|
| Attention Model 번역 및 정리 (0) | 2020.02.10 |
| Intro to Encoder-Decoder LSTM(=seq2seq) 번역 및 정리 (2) | 2020.02.08 |
| [DL Wizard] Long Short-Term Memory (LSTM) network with PyTorch 번역 및 정리 (0) | 2020.02.08 |
| [DL Wizard] Recurrent Neural Network with PyTorch 번역 및 정리 (0) | 2020.02.08 |