2020. 2. 10. 14:42ㆍnlp
출처
1) Neural Machine Translation By Jointly Learning to Align and Translate
2) Attention: Illustrated Attention
3) Attention and Memory in Deep Learning and NLP
기존 Encoder-Decoder RNN/LSTM 모델의 문제점
- 아무리 긴 input sentence가 주어져도 고정 길이 벡터fixed-length vector로 압축해서 표현해야 함
- Decoder는 Encoder의 마지막 은닉상태만 전달받음 → 엄청 긴 문장이라면 엄청 많이 까먹음


기존 Encoder-Decoder RNN/LSTM 모델의 문제점 해결
- 고정길이벡터 X
- input sentence는 여러 벡터의 sequence로 encoding되고 Decoder는 해당되는 time-stamp에 맞춰 이 sequence 중 일부분(subset)만 보고 참고함
- Decoder가 output 예측할때, [input embedding 중 지금 decoding 하는 곳에 해당하는 부분] + [그 전까지 Decoder가 생성한 output들] 을 참고함
* 해당하는지 아는 방법? Weighted Sum ( 현재 Decoder에 해당하는 부분의 은닉상태엔 score/가중치 크게, 아니면 작게)
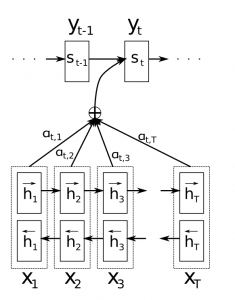
- Attention은 Encoder와 Decoder 사이에 있으며, Decoder에게 (Encoder의 마지막 은닉상태뿐만 아니라) Encoder의 (모든) 은닉상태를 전해줌
* Attention의 두 종류 1) global attention 2) local attention
1) global attention : Encoder의 모든 은닉상태를 Decoder에 전해줌
2) local attention : Encoder의 일부 은닉상태를 Decoder에 전해줌

학습할 때 : 각 time-stamp t에 Decoder의 input은 그 전 time-stamp (t-1)에서 정답으로 주어진 output
추론(테스트)할 때 : 각 time-stamp t에 Decoder의 input은 그 전 time-stamp (t-1)에서 예측한 output
Attention 모델의 Encoder = bidirectional RNN
- 이전에 온 단어뿐만 아니라 이후에 올 단어까지 summarize한 embedding 만듦
- [input sentence 순서 그대로 embedding한 것] + [input sentence 순서 거꾸로해서 embedding한 것]
- RNN은 recent input을 더 잘 표현
- 따라서 h_j = j번째 은닉상태 : j 번째 단어에 가장 focused된 embedding, 그러나 그 전+그 후 단어의 embedding도 약간 반영됨
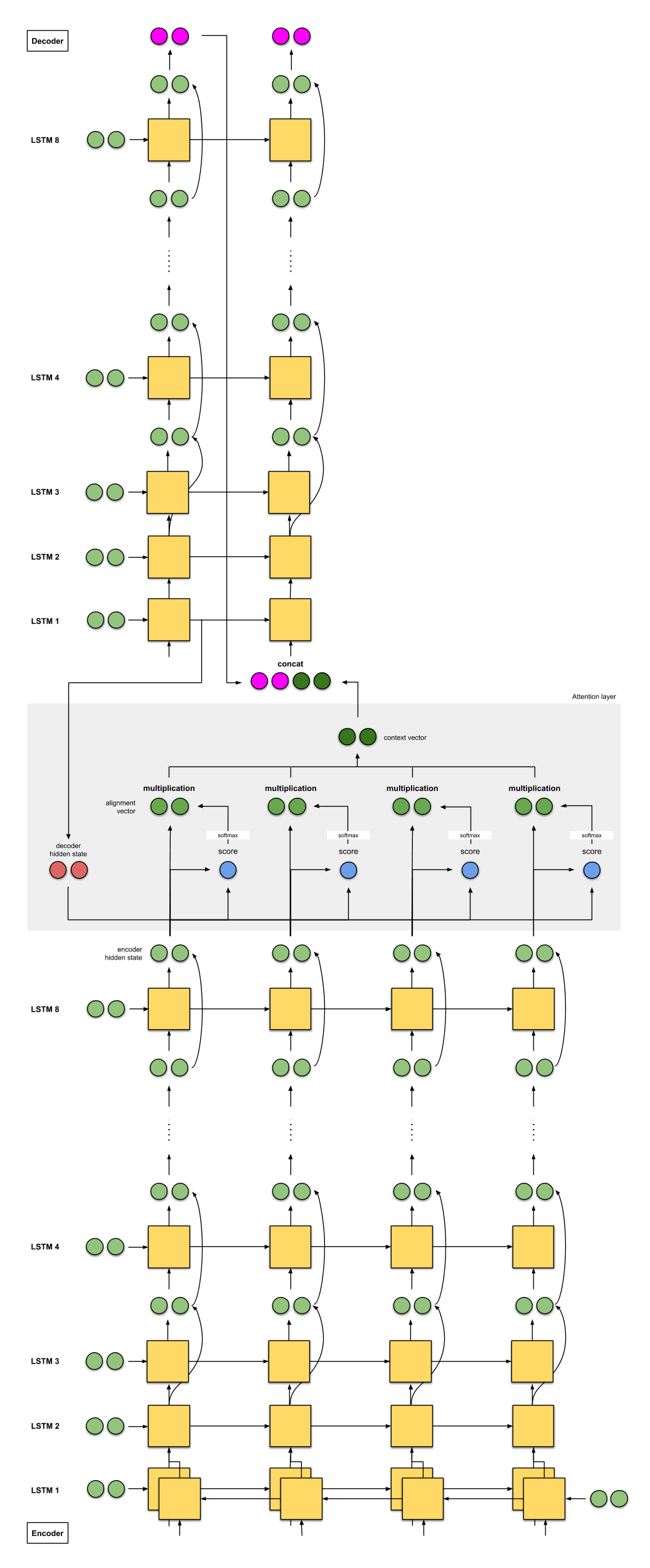
[모델 예시] Google's Neural Machine Translation (GNMT)
- Enocoder : 8 LSTMs (첫번째 LSTM은 Bidirectional)
- Decoder : 8 LSTMs
'nlp' 카테고리의 다른 글
| 그림으로 보는 Transformer 번역 및 정리 (0) | 2020.02.10 |
|---|---|
| [seq2seq + Attention] 불어-영어 번역 모델 PyTorch로 구현하기 (0) | 2020.02.10 |
| seq2seq 모델 PyTorch로 구현하기 번역 및 정리 (9) | 2020.02.09 |
| Intro to Encoder-Decoder LSTM(=seq2seq) 번역 및 정리 (2) | 2020.02.08 |
| [DL Wizard] Long Short-Term Memory (LSTM) network with PyTorch 번역 및 정리 (0) | 2020.02.08 |