2019. 12. 4. 14:34ㆍnlp
Language Model(=LM) : 문장 또는 단어의 연쇄의 확률을 계산하는 것
1) Chain Rule
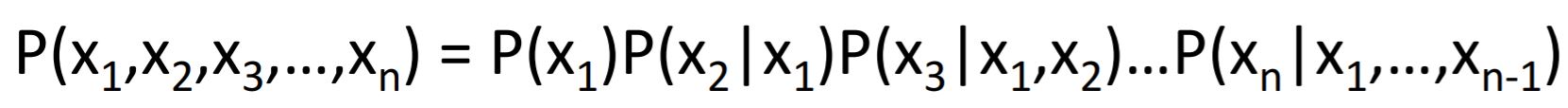

2) Markov Assumption

(ex) Unigram Model
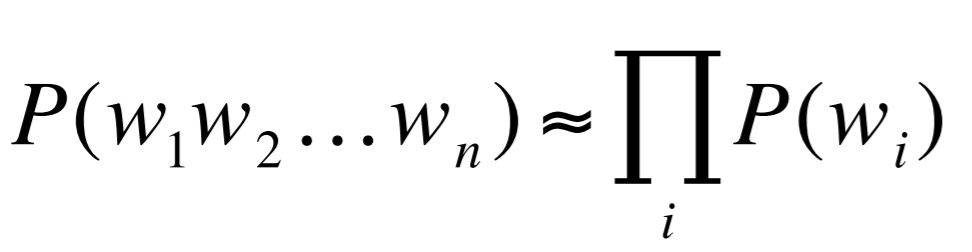
(ex2) Bigram Model

Bigram의 Maximum Likelihood Estimate

이러한 LM의 문제점
1) 언어는 long distance dependency : 한 단어로부터 엄청 멀리 있는 단어에게도 영향을 받는다
2) 일반화 능력이 부족하다 : training data와 test data에 쓰이는 단어들이 같아야만 성능 좋음, 유의어 고려 못 함
이에 대한 해결 방법
1) Add-one (Laplace) Smoothing : 모든 단어를 한 번 더 본 셈 친다


* N-gram처럼 0이 너무 많은 분야에선 쓰이지 않음. text-classification에선 쓰인다.
2) Back-off : trigram으로 확률 계산 → trigram 없으면 bigram으로 대신 → bigram도 없으면 unigram으로 대신
3) Interpolation : unigram + bigram + trigram 모두 찔끔씩 사용

*lambda는 hyper-parameter의 일종. 이러한 hyper-parameter의 값을 정하기 위해서 cross-validation을 한다. cross-validation은 training set을 n개로 쪼개고 첫 번째 덩어리만 빼고 트레이닝, 두 번째 덩어리만 빼고 트레이닝, ... n번째 덩어리만 빼고 트레이닝 하는 방법이다.
Language Model의 성능 측정하기
1) Extrinsic Evalutaion : 두 모델의 정확도 비교하기 → 시간 너무 오래 걸림 :(
2) Intrinsic Evaluation : 모델의 혼잡도(perplexity) 측정하기 (혼잡도 낮을수록 확률 높은 것 ∴혼잡도 낮은 모델이 좋은 모델)

※ 출처
1) 글 버전
2) PPT 버전
'nlp' 카테고리의 다른 글
| Vector Semantics (0) | 2019.12.04 |
|---|---|
| Naive Bayes and Text Classification (0) | 2019.12.04 |
| Minimum Edit Distance (0) | 2019.12.04 |
| 정규표현식 정리 (0) | 2019.12.04 |
| 넷플릭스/네이버 시놉시스 어휘 단계 분석하기 (0) | 2019.11.11 |