2019. 12. 4. 16:16ㆍnlp
1) word sense : 단어의 의미
2) synonym (ex) couch와 sofa
* principle of contrast : 형태 다르면 의미도 다르다
3) word similarity (ex) dog와 cat
3) relatedness (또는 association) (ex) cup과 coffee
4) lexical fields (어휘장) (ex) 의사와 매쓰
단어의 의미란? 단어의 사용(use), 즉 문맥에 따라 달라진다.
(ex) Labov : 컵이란 무엇인가?
∴ 단어의 의미는 neighboring word를 통해 알 수 있다. "한 단어 = 그 단어의 이웃 단어를 벡터로 나타낸 것"
[ Vector Semantics ]
1. Long, sparse vector : count로 벡터 만듦
1.1. Tf-idf (Term frequency-Inverse document frequency)
1.2. PPMI (Positive Pointwise Mutual Information)
2. Short, dense vector : binary classifier(이웃 단어냐 아니냐)의 weight로 벡터 만듦
2.1. Word2Vec : CBOW(Continuous Bag Of Words), Skip-gram
2.2. Fasttext
2.3. Glove
1. Long, sparse vector
1.1. Tf-idf
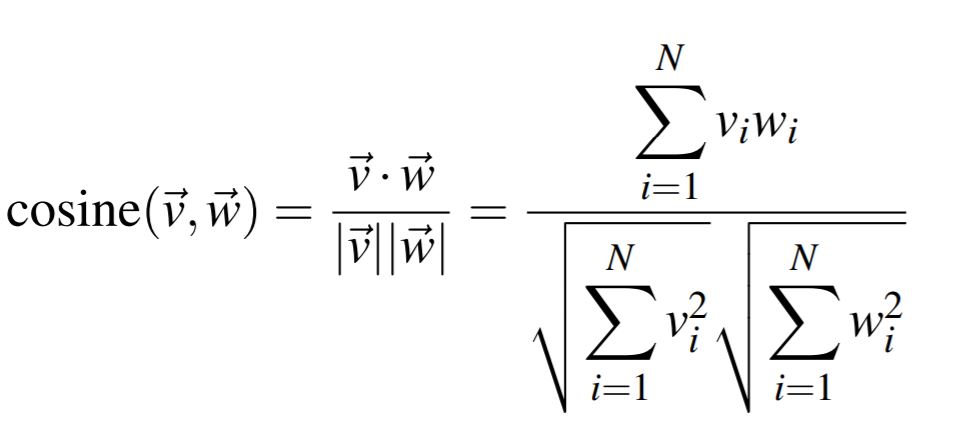
두 단어(또는 두 벡터)의 유사성 계산하기 < Cosine Similarity >
- 두 벡터를 내적하여 유사성 구함 (같은 방향을 향하면 유사한 단어)
- 두 벡터의 길이로 나눠 표준화 (길이로 나누지 않으면 빈도 높은 단어가 온갖 단어랑 다 similarity 매우 높음)
- 각 벡터의 요소들은 모두 frequency, 따라서 0 이상. 그러므로 cosine 값은 0과 1 사이
- 0이면 의미 유사하지 않음, 1일수록 의미 유사한 단어
그러나 단순 빈도는 효과적이지 않음.
Frequency Paradox : 빈도 높은 단어일수록(많이 쓰이는 단어일수록) 별 의미 없다 (ex) a, the
Tf-idf = tf * idf
* idf는 흔히 쓰이는 단어일수록 0에 가까워지고, 잘 안 쓰이는 단어일수록 값이 커짐
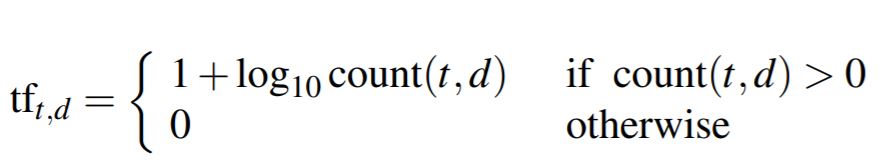
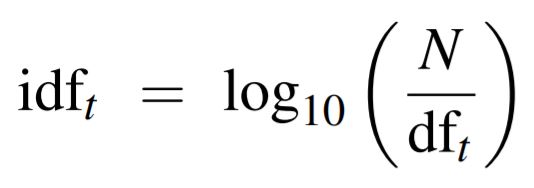
1.2. PPMI
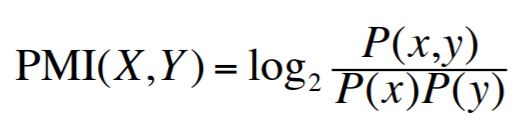
두 단어가 독립적이라고 가정했을 때보다 둘이 같이 등장하는 경우가 더 많은가?
PMI 값이 음수면 해석 어려움. 그래서 음수면 다 0으로 퉁치자 → PPMI
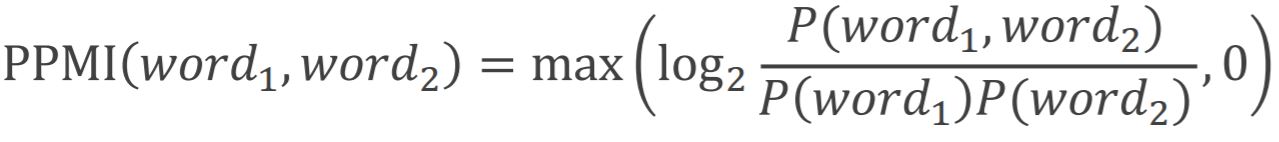
PPMI의 문제점
1) 두 단어가 완전 독립일 경우 : 분자 P(x,y) = P(x) * P(y), 분모와 같음 ∴ PMI 값이 0이 됨
2) 두 단어가 완전 종속일 경우 : 분자 P(x,y) = P(x) ∴ PMI 값은 log(1/P(y)) → y의 빈도가 낮을수록 PMI값 커짐(biased)
PPMI 해결방법
1) Add-one (Laplace) Smoothing
2) Weighting PMI : 빈도 낮은 단어는 좀 더 높은 확률로, 빈도 높은 단어는 좀 더 낮은 확률로 만들기
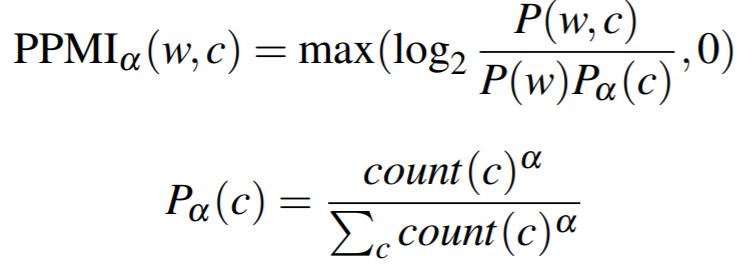
2. Short, dense vector
2.1. Word2Vec
Word2Vec의 2가지 방식 : CBOW와 Skip-gram
1) CBOW : context word가 주어졌을 때 target word를 예측함
2) Skip-gram : target word가 주어졌을 때 이 단어가 context가 맞는지 아닌지 예측함
Skip-gram
1) V개(단어 개수)의 300 차원 벡터 만들기 (랜덤한 숫자로 initial embedding)
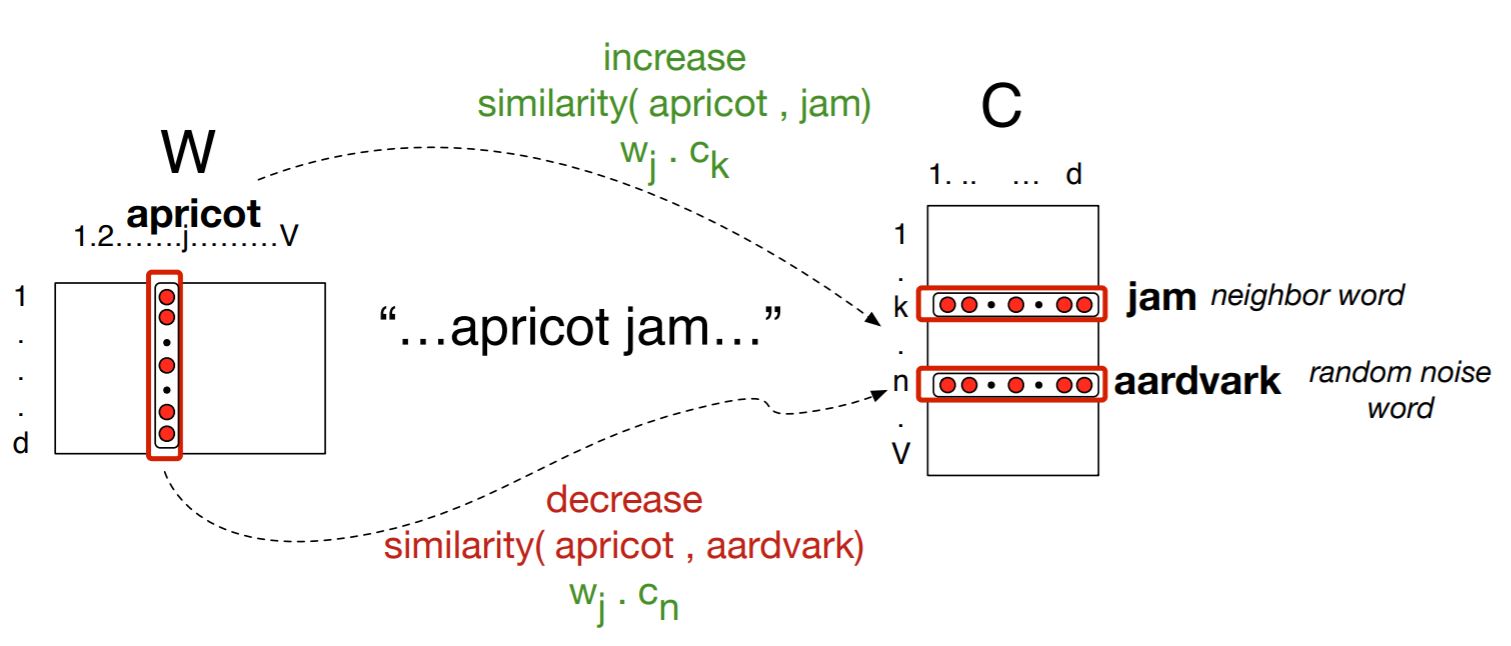
2) Positive Example : target word + 이웃하는 단어 (window size에 따라 어디까지 이웃하는 걸로 볼지 달라짐)
* window size가 작으면 target word와 의미 유사하고 품사도 같은 단어(syntax), window size가 적당히 크면 문장의 topic과 유사한 단어가 나온다(semantics)
3) Negative Example : target word + 이웃하지 않는 아무 단어(noise word) *
4) Logistic Regression으로 Positive / Negative 구분하는 classifier 학습시키기 + Gradient Descent Algorithm
5) Classifier의 weight를 embedding으로 사용
* noise word 선택 방법
1) unigram frequency : 단순 빈도로 랜덤하게 뽑기
2) P_a(W) : 빈도 낮은 단어는 좀 더 높게, 높은 단어는 좀 더 낮게 보정 후 랜덤하게 뽑기
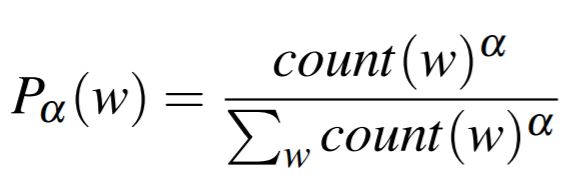
Skip-gram 학습하기
* t = target word, c = context word
* target과 context가 positive example일 확률 = 두 단어의 similarity 정도
* 두 단어 벡터의 내적으로 similarity 구할 수 있음. 그러나 확률은 아님. 확률로 만들어주기 위해 시그모이드 함수에 내적값을 넣어줌

목표는 positive example에서 나온 것을 +로, negative example에서 나온 것을 -로 분류하는 것. 따라서 아래 수식의 값을 최대화해야 한다
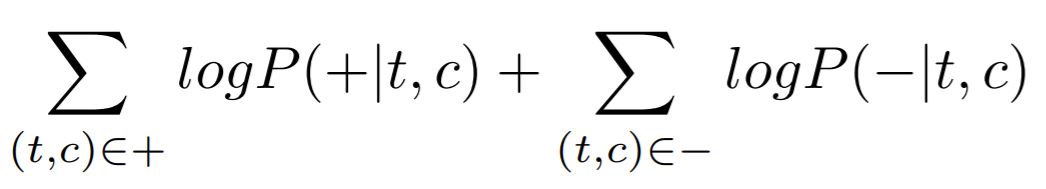
하나의 target word에 관한 식은 다음과 같이 쓸 수 있다. 하나의 positive example에 여러 negative example이 대응된다.
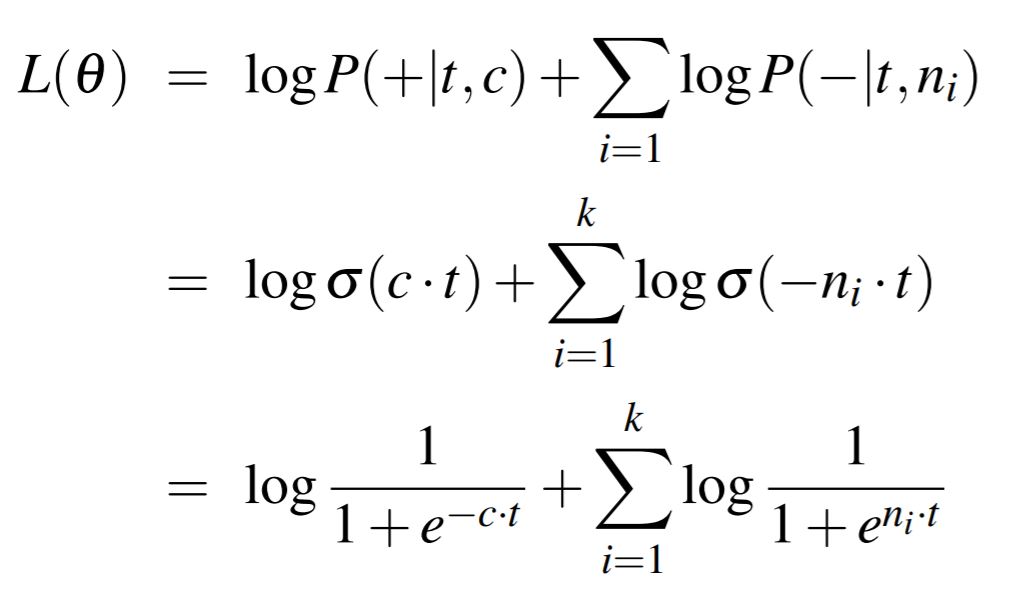
Word2Vec과 Fasttext의 차이점 : token 단위 vs character 단위
"the cat"이라는 스트링을 word2vec은 "the"와 "cat"으로 나누어 생각하는 반면, Fasttext는 "th", "he", "ca", "at" 으로 나누어 생각한다. sub-word 정보로 형태학적 분석이 가능하다. 따라서 처음 본 단어도 분석할 수 있다.
(ex) unlikely를 un-, like-, -ly로 분석하여 원래 알던 의미를 조합하여 이해할 수 있다.
Word2Vec과 Glove의 차이점 : local vs global co-occurence
※ 출처
1) 글 버전
'nlp' 카테고리의 다른 글
| Maximum Entropy Model (0) | 2019.12.04 |
|---|---|
| Entropy (0) | 2019.12.04 |
| Naive Bayes and Text Classification (0) | 2019.12.04 |
| Language Modeling (0) | 2019.12.04 |
| Minimum Edit Distance (0) | 2019.12.04 |