2020. 1. 14. 12:45ㆍstats
SNUON 통계학
범주형 자료의 추론
1. 일표본비율에 관한 추론
2. 이표본비율의 차이에 관한 추론
3. Goodness of fit test와 카이제곱 분포
4. 분할표에서 독립성 검정
5. 소표본에서 표본비율에 관한 검정
6. 역학 (epidemiology) 에서 2*2 분할표 분석
15-1. 적합성 검정과 카이제곱 분포 (예제)
Small Sample inference for a proportion
2009 이란 선거결과
- 2009년 이란 선거에 선거부정이 있었는지 알아보자
- 출구조사(관측치) vs 실제 선거 결과(기댓값 = 득표율 * 출구조사 인원)
- Observed # vs Expected #

가설검정
- H_0 : The observed counts from the poll follow the same distribution as the reported votes
- H_A : The observed counts from the poll do not follow the same distribution as the reported votes
Calculation of the test statistic


근사치 계산
카이제곱 분포의 평균 = df, 분산 = df*2
또한 카이제곱 분포도 정규분포에 근사함
이 경우 평균 = df = 3-1 = 2, 분산 = 2*2 = 4, 표준편차 = √4 = 2
정규분포라면 2+1.96*2 ≒ 6 까지가 95% 신뢰구간
이에 비해 30.89는 매우 큰 숫자
따라서 귀무가설 기각 가능
p-value가 0.05보다 작으므로 귀무가설을 기각한다
즉 투표부정이 있었을 가능성이 존재한다
15-2. 분할표에서 독립성 검정
Chi-Square Test for Independence
Popular Kids
4-6학년 학생들에게 성적, 운동, 인기 중 가장 중요한 것이 무엇인지 물어보았더니 그 결과는 다음과 같았다. 학년별로 선호도의 차이가 있는가?
<2차원 분할표>
| 성적 | 인기 | 운동 | |
| 4학년 | 63 | 31 | 25 |
| 5학년 | 88 | 55 | 33 |
| 6학년 | 96 | 55 | 32 |
Chi-Square Test for Independence
가설검정
- H_0 : Grade and goals are independent. Goals do not vary by grade.
- H_A : Grade and goals are dependent. Goals vary by grade.
- 검정통계량

k = number of cells (9)
R = number of rows (3)
C = number of columns (3)
4학년의 총 인원과 성적, 인기 칸 인원을 알면 운동 칸 인원은 자동으로 정해짐
5학년의 총 인원과 성적, 인기 칸 인원을 알면 운동 칸 인원은 자동으로 정해짐
성적이 중요한 총 인원과 4학년 성적 칸, 5학년 성적 칸을 알면 6학년 성적 칸 인원은 자동으로 정해짐
...
따라서 3*3 분할표에선 2*2 칸만 자유롭게 정할 수 있음
그래서 df = (R-1) * (C-1)
Expected counts in two-way tables
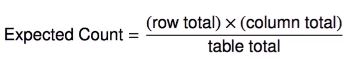

[4학년인 사건] 과 [성적이 가장 중요할 사건] 이 독립이라면, [4학년 & 성적 가장 중요]일 확률은 두 사건의 확률을 곱한 것
4학년일 확률 = 119 / 478 = ( row total ) / table total
성적이 가장 중요할 확률 = 247 / 478 = ( column total ) / table total
이 확률에 총 인원인 table total 을 곱하면 기댓값이 나옴
( row total ) / table total * ( column total ) / table total * table total
= ( row total ) * ( column total ) / table total
(ex) 첫 번째 셀의 기댓값 = 119 * 247 / 478 = 61
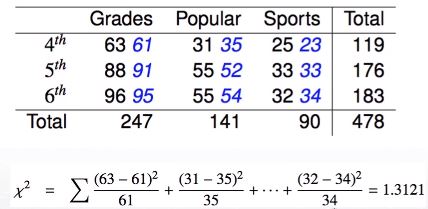
자유도는 (3-1) * (3-1) = 2*2 = 4
카이제곱 분포의 평균 = 자유도 = 4
검정통계량(1.3121)이 카이제곱 분포의 평균보다도 작기 때문에 귀무가설을 기각할 수 없다
R
pchisq( q=1.31, df=4, lower.tail=F)
# 0.8596766
15-3. 소표본에서 표본비율에 관한 검정
족집게 문어 Paul은 정말 예언능력이 있는가?
- Paul이 있는 수족관에 각국의 국기가 그려진 투명한 상자 안에 홍합을 넣어 Paul이 먹는 쪽에 있는 국기가 승리
- 예언능력이 전혀 없는 경우 Paul이 독일의 월드컵 결기 결과(8경기)를 다 맞출 확률은?
가설검정
- H_0 : p = 0.5
- H_A : p > 0.5
Conditions
- Independence : We can assume that each guess is independent of another
- Sample size : The number of expected successes is smaller than 10 ( 8*0.5 = 4)
→ 표본크기가 크지 않기 때문에 중심극한정리를 사용할 수 없다. 따라서 simulation을 이용한다
Simulation
Paul이 예지능력이 있는지 여부에 대한 가설검정을 할 경우 p-value를 계산하는 방법은?
a. 동전을 8번 던지고 앞면이 나오는 횟수를 기록한다
b. 위의 과정을 1000번 반복한다
c. 앞면이 8번 나오는 비율을 계산한다 (sampling distribution)
d. 8번 모두 나온 경우, 즉 비율이 1인 경우가 1000번 중 몇 번인지를 계산한다

- Paul이 예언능력이 없다면 8 경기 모두 맞출 확률은 0.0037
( p값은 귀무가설이 참일 때, 같은 결과+더 extreme한 결과를 목격할 확률)
- 귀무가설을 기각한다. 즉 자료는 Paul이 예지능력이 있다는 증거를 제시한다
- Type 1 error를 범할 가능성이 있다 ( p-value가 0은 아니니까)
사람들이 정말 자신의 손등을 잘 알고 있는가?
MythBuster의 실험에서 10개의 손등을 보여준 후에 피실험자들에게 본인의 손등을 고르게 하였다
12명 중 11명이 자신의 손등을 고르는데 성공했다 (p_hat = 11/12 = 0.9167)
- H_0 : p=0.10 (random guessing)
- H_A : p > 0.10 (better than random guessing)
Conditions
- Independence : We can assume that each person's guessing is independent of another
- Sample size : The number of expected successe is smaller than 10 (12 * 0.1 = 1.2)
→ 표본크기가 크지 않기 때문에 중심극한정리를 사용할 수 없다. 따라서 simulation을 이용한다
Simulation scheme
a. 10면 주사위를 사용하여 1이 나온 경우를 성공, 그 이외의 경우를 실패라고 하자
b. 주사위를 12번 던진 후 1이 나온 횟수를 기록한다
c. b단계를 1000번 반복한 후 1이 나온 비율을 계산한다 (sampling distribution)
d. 비율이 0.9167 (the observed proportion) 이상인 경우가 p-value이다
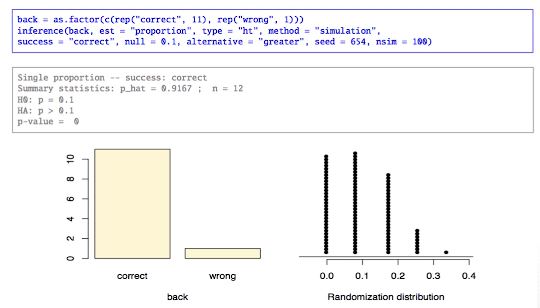
따라서 귀무가설 기각 가능. 사람들은 본인의 손등을 알아본다.
15-4. 소표본에서 두 표본비율의 차이에 관한 검정
Small Sampe Inference for a Difference Between Two Proportions
Comparing back of the hand to palm of the hand
MythBusters 쇼에서 손바닥에 대해서도 같은 실험을 하였다. 이번에는 (다른) 12명 중 7명이 본인의 손바닥을 맞추었다.
| 손등 | 손바닥 | 총합 | |
| 맞춤 | 11 | 7 | 18 |
| 틀림 | 1 | 5 | 6 |
| 총합 | 12 | 12 | 24 |
손등을 맞춘 확률 = 11/12 = 0.916
손바닥을 맞춘 확률 = 7/12 = 0.583
차이 : 손등을 맞출 확률이 33.3% 더 높음
손등을 알아보는 비율과 손바닥을 알아보는 비율에 차이가 있는가?
가설검정
- 귀무가설 : 손등 알아보는 확률 = 손바닥 알아보는 확률
- 대립가설 : 손등 알아보는 확률 != 손바닥 알아보는 확률
Conditions
- Independence : within groups, between groups 모두 독립이라 가정
- Sample size : p_hat = (11+7) / (12+12) = 18/24 = 0.75
(손등, 손바닥에 차이가 없다고 가정하면 알아볼 확률 0.75)
- 손등 집단의 성공 기댓값 = 12*0.75 = 9 , 실패 기댓값 = 3
- 손바닥 집단의 성공 기댓값 = 12*0.75 = 9 , 실패 기댓값 = 3
→ 표본크기가 크지 않기 때문에 중심극한정리를 사용할 수 없다. 따라서 simulation을 이용한다
(np=기댓값 >= 10 을 만족하지 않으므로 simulation)
Simulation scheme
1) 24 index card를 사용한다. 여기서 카드는 피실험자
2) 이 중 18개의 카드에 "맞음", 나머지 6개의 카드에 "틀림"이라고 표기
3) 카드를 섞은 후에 12개씩 두 개의 그룹으로 나눈다
4) 두 개의 그룹에서 "맞음"의 비율을 계산한 후 그 차이를 기록한다
5) 3,4 단계를 1000번 반복한 후 sampling distribution을 구한다
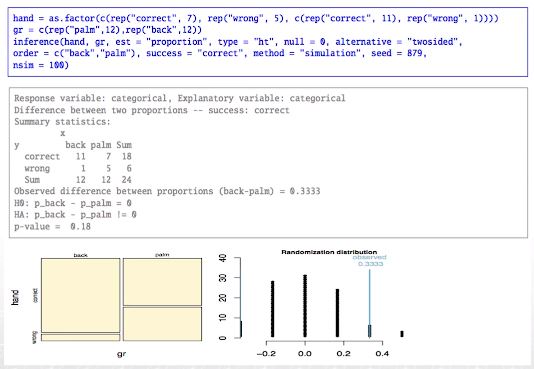
귀무가설 기각 불가능. 손등/손바닥 구별 능력에 차이가 있다고 할 수 없다.
'stats' 카테고리의 다른 글
| 17. 회귀분석 II (0) | 2020.01.15 |
|---|---|
| 16. 회귀분석 I (0) | 2020.01.15 |
| 14. 모비율에 관한 추론 I (0) | 2020.01.12 |
| 13. 분산분석 ANOVA (0) | 2020.01.11 |
| 12. 모평균에 관한 추론 II (0) | 2020.01.07 |